で、マイクロプロセッサです。これがどのように発展してきたかについての一
般的な解説とかはいくらでも良い本があるので、ここではそれがスーパーコン
ピューティングにとってどういう意味があるか、という偏った観点からの話を
します。
マイクロプロセッサというものが考えられたのは、良く知られているように
日本の会社である ビジコムが、電卓に搭載するためのカスタム LSI の開発を
当時はメモリくらいしか作ってなかった Intel に依頼したところから始まっ
ています。このあと色々経緯があるわけですが、インテルの技術者とビジコム
から出向いた嶋が共同で、カスタム LSI の代わりに基本的なプログラムでき
る計算機の機能をもった 4004 チップを開発することになります。
これは 1971 年のこと、 pMOS プロセス  ルールで、わず
か 2300 トランジスタのものでした。まだ CMOS ではないのですが、 MOS プ
ロセスを採用することで低速ですが集積度の高い LSI を実現できたことが
1チップで 2300 ものトランジスタを集積することを可能にしたのです。
ルールで、わず
か 2300 トランジスタのものでした。まだ CMOS ではないのですが、 MOS プ
ロセスを採用することで低速ですが集積度の高い LSI を実現できたことが
1チップで 2300 ものトランジスタを集積することを可能にしたのです。
この時期最新鋭のスーパーコンピューターであった CDC 7600 は LSI どころ
か IC 以前の設計であり、 1976 年の Cray-1 で初めて IC が使われました。
しかし、それはわずか 4 ゲート程度、 16 トランジスタ相当のものでした。
つまり、この時点でチップ当りのトランジスタ数は 100 倍ほど違ったことに
なります。
もっとも、動作クロックは Cray-1 の 80MHz に対して 4004 は 108kHz でほ
ぼ 1000 倍違いました。従って、この時点では処理能力という観点では
Cray-1 で使った IC のほうが高いものであったわけです。単純に考えると処
理能力は速度とトランジスタ数の積になるわけですから。
その後の進歩はしかし非常に違うものとなりました。重要な点の1つは、
CMOS ではプロセスを微細化してトランジスタを小さくすると動作速度も速く
なる「スケーリング則」があるのに対して Cary-1 で使われた ECL 等のバイ
ポーラ技術ではあんまりそういうことはなく、速度は配線遅延で決まるところ
が大きくて、配線の長さは発熱密度で決まる、というふうになっていたことで
す。
このため、 CMOS 技術を使ったマイクロプロセッサでは LSI としての潜在的
な処理能力、つまりトランジスタ数と速度の積ですが、は非常に急激に増加し
ます。
いわゆるムーアの法則では、計算機の速度は 1.5 年で倍、となってますが、
上の意味での処理能力の進歩はもっとずっと速いものです。 1990 年をみてみ
ると、CMOS プロセッサは 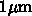 ルール、100万トランジスタ、
50MHz の動作速度に達しています。トランジスタ密度では 100 倍にしかなっ
てないのにトランジスタ数は増えているのは、チップサイズが大きくなったの
が主な理由です。動作速度は 500倍にもなっていますが、これは 4004 が遅かっ
たためでその後継(正確にいうとさらのその次)で 8 bit プロセッサになった
8080(1974年) では MHz を超えています。なので、その後の15年間では 10倍
程度、ということになって、スケーリング則から大きくはずれていません。
ルール、100万トランジスタ、
50MHz の動作速度に達しています。トランジスタ密度では 100 倍にしかなっ
てないのにトランジスタ数は増えているのは、チップサイズが大きくなったの
が主な理由です。動作速度は 500倍にもなっていますが、これは 4004 が遅かっ
たためでその後継(正確にいうとさらのその次)で 8 bit プロセッサになった
8080(1974年) では MHz を超えています。なので、その後の15年間では 10倍
程度、ということになって、スケーリング則から大きくはずれていません。
いずれにしても、20年間でトランジスタ数は 500倍、クロックも500倍になっ
て、25万倍です。ムーアの法則だと20年間でほぼ1万倍なので、だいぶ低い数
字になります。
ここで、スーパーコンピューティングという観点からは、浮動小数点演算の速
度が重要です。CMOS VLSI で意味がある速度を実現したのは
AMD Am7902 等(要確認)ですが、ここでは Intel 8086 16ビットプロセッサの
コプロセッサとして開発された 8087 を取り上げることにします。 8086 は
8080 の拡張版であり、ビット数の少ないプロセッサを無理矢理倍に拡張する
という、その後 64 ビットプロセッサになった現在までひきずることになる方
針で成功を収めたものです。
Intel がどういうマーケットを想定して 8087 を開発したのかは明らかではあ
りませんが、 8087 の実装は IEEE 標準で現在はあらゆる計算機で使われてい
る浮動小数点形式をほぼ初めて実装した(8087の実装は IEEE 標準確定前に行
われた)ものとしても重要な意味があります。それまでは、例えば CDC 7600
の浮動小数点形式は IBM 360/195 の浮動小数点形式とは違っており、また丸
めのやり方も0にむかって切り捨てるとかマイナス無限大にむかって切り捨て
るとか色々でした。 IEEE 標準では、「バイアスのない四捨五入」を定義して、
理論的におかしなところがない丸めを標準化した他、無限大、非数等の概念を
導入した、いくつかの超越関数に対して、「最終ビットまで正しい」ことを標
準として要求した、等重要な意義がありました。もっとも、これらの標準は、
速度よりも精度を重視するきらいがあり、アプリケーションによっては個々の
演算の精度が多少落ちても速く計算できるほうが結局良い精度になる場合もあ
る、といった重要な観点が抜け落ちている、という問題はありました。
さて、 8087 です。 8087 はビットパターンによって演算にかかるサイクル数
が変わる代物なので演算性能がいくつ、といいにくいのですが、 30kflops 前
後であったようです。これに対してほぼ10年後の 1989 にでてきた 80860 は
60Mflops で、 2000倍になっています。これは、この時期までは上で述べたト
ランジスタ数とクロック速度の積にほぼ比例して性能が向上していた、というこ
とを意味しています。実際はそれよりもう少し高いです。
このように急速な性能向上が実現できた理由は簡単で、 80860 までは1つの演
算器の速度を上げるのに増えたトランジスタを使うことができたからです。
浮動小数点演算には乗算と加算がありますが、普通に人間が筆算するのと同じ
で乗算のほうが大変であり、早くやるにはそれだけのハードウェアがいります。
計算機での乗算の方法というのは、基本的には人間が筆算するのと同じで、
一方の数字と、他方の数字の1桁を掛けたものを桁数だけ作って、それらを全
部加算するわけです。 単純には、ビット長だけの加算器が1つあって、それが
ビット長だけのサイクルを使って加算する、ということになります。加算器を
2つ使って2個づつ積算すれば、時間は半分ですみます。 ビット数だけ加算器
を並べて一辺に加算すれば、1サイクルで加算できることになります。但し、
加算の順番を工夫しないと時間がかかります。順番を工夫し、さらにパイプラ
イン化することでサイクルタイムを短くする、というふうに普通しています。
このように、1つの演算をなるべく速くする、ということができる範囲では、
演算速度はトランジスタ数の増加以上に増えます。 これは単に、加算器の数
を倍にしてもトランジスタ数は倍にならないからです。他の制御回路や、レジ
スタファイル等は演算器が大きくなっても回路規模は比例しては増えません。
これは、実は Cray-1 までのスーパーコンピューターの進歩を繰り返したこと
になります。スーパーコンピューターと結構違うのはクロックがどんどん上がっ
たことですが、計算機の構成自体は、特に浮動小数点演算につてみる限り、要
するに1サイクルで演算ができて完全パイプライン動作するようになるまで大
きくする、というだけです。
なお、 x86 系では 32ビットになった 386, その高速版の 486 と進化したわ
けですが、パイプライン化した浮動小数点演算器をもつのはその次の Pentium
からになります。
その後 15年の、 2006年現在までの進化を考えてみましょう。2006年夏の時点
では Intel Core 2 Duo が浮動小数点演算ピーク性能は高く、1チップに2コア
あってそれぞれ4演算づつするので 3GHz クロックのもので 24 Gflops のピー
ク性能を持ちます。 これは 40MHz の 80860 の400倍で、必ずしも悪くはない
のですが問題がないわけではありません。トランジスタ数は300倍(チェック必
要)になっているのに、クロック当りの演算数は 4 倍にしかなっていないから
です。これに対して、クロック周波数は 75倍になっていて、半導体の速度向
上以上に上がっています。これは、 Cray-1 以降のスーパーコンピューターの
進化とは非常に異なっていて、その違いが、何故現在スーパーコンピューター
は普通の PC のマイクロプロセッサを並べるものになったのか、ということの
理由になっています。
バイポーラ素子を使ったベクトル機では、クロック周波数が 1GHz を超えるも
のは実現していません。これには色々な理由がありますが、結局はチップ間に
沢山配線があるものでそこまでクロックを上げるのは現実的ではないし、といっ
て1990年代前半のバイポーラ素子では1チップにベクトル計算機の全ての機能
を収めるのは困難だったからです。これに対して、CMOS マイクロプロセッサ
では始めから1チップですから、外とのデータ交換のことを考えずにクロック
速度をどんどん上げてしまうことができます。これが必要になったのは Intel
では 80486 からで、外部バスに対して内部動作クロックが2倍とか4倍のもの
ができました。もちろん、これにより演算速度に対して相対的にメモリデータ
転送速度は遅くなるので、ベクトル計算機が得意とするような単純な配列演算
では速度が低下します。が、まあ、頑張ってキャッシュとか使うプログラムを
書ければそんなに速度は落ちないはず、という話だったわけです。まあ、これ
は一般にはそんなに上手くいかないのですが、とにかくマイクロプロセッサの
設計はそういう方向で進んでいくことになりました。
これは Intel x86 だけに限ったことではなく、基本的にあらゆるマイクロプ
ロセッサはこの方向にいくことになりました。 80860 ではまだこの考え方は
なく、メモリから1クロックサイクルに1語転送可能という Cray-1 並のシステ
ムだったのですが、その後急速に相対的なメモリ転送能力は低下することにな
ります。
この時期のもうひとつ重要な変化は、Intel x86 系のシステムが最初は価格性
能比、そしてすぐに絶対性能でも、より高価な RISC プロセッサを上回るよう
になったことです。
RISC というのは新しい考え方ではない、というのは Cray が設計した CDC
6600 の項で既に述べたことですが、実は1980年前後の初期の RISC (Stanford
MIPS やSun SPARC の原型となった Berkley RISC)は CDC6600 よりもさらにシ
ンプルなもので、 6600 は 90年以降にでてくる superscalar 型プロセッサに
近いものになっています。
RISC とはではどういうものか、というと、以下のような特徴をもつプロセッ
サアーキテクチャです。これはあまり厳密なものではないですが、
-
命令が固定長である。
-
実行パイプラインが固定段数である。つまり、命令はマイクロコードではなくハードワイヤード論理で実行される。
-
汎用レジスタを持ち、演算はレジスタ間、メモリ・レジスタ間は転送命令である。
-
1クロックに1命令が投入される。
-
条件分岐もパイプライン処理される。
つまり、このような特徴をもたないものが非 RISC、あるいは CISC と呼ばれ
る計算機アーキテクチャである、ということになります。
ここで重要なのは、マイクロコードを基本的にはもたない、ということです。
マイクロコードとはそもそもなにか、というのが問題ですが、これは、非
RISC な計算機アーキテクチャでは、「機械語」というのがそのまま実行され
るわけではなく、多くの命令は実際にはより低いレベルのサブルーチンのよう
なものの呼び出し、という形で実行されていて、そのサブルーチンのことをマ
イクロコードという、というような感じのものです。サブルーチンといっても、
普通のソフトウェアでのサブルーチンと違ってそこから先はハードウェアで解
釈されるので結構高速です。例えば、ハードウェア乗算器をもたないプロセッ
サで乗算するのは、加算器を繰り返し使うわけですが、そのためのマイクロコー
ドからしか使えないレジスタとかがあってそれを使うプログラムを書いて乗算
するわけです。また、メモリ転送とかでも長さを指定するオペランドがあって、
その指定に従ってループを回る、といったことがマイクロコードではできます。
VAX アーキテクチャでは、多項式評価命令、なんてものがあって、それを使う
と浮動小数点演算ユニットの理論ピークに近い性能がでる、逆にいうと普通の
プログラムではまず性能がでない、といったこともありました。この、マイク
ロプログラム方針というのは、比較的複雑な、あるいはハードウェアで実現し
ようとすればハードウェアが大規模になりすぎるような命令を、小規模なハー
ドウェアで実現することを可能にしたもので、 IBM 360 や DEC VAX のような、
同じ命令セットで性能が違う製品系列を作ることを可能にする、あるいは世代
が変わっても前の命令セットと互換性をとることを可能にする、というような
意味で、機械語プログラムの再利用性を高める重要な技術でした。もちろん、
機械語でのプログラム開発自体も、1つの命令が複雑な処理をしてくれる分容
易になります。また、機械語が短くなるので、少ないメモリでプログラムが収
まる、というのも重要なメリットでした。
但し、コンパイラを使うことを考えるとそういう複雑な命令が可能なことがい
いかどうか、が問題になります。例えばコンパイラが Fortran や C のソース
プログラムをみて、「これを多項式の計算だ」と判定して多項式の計算機命令
を出す、なんてのはあまりありそうにない話だからです。もちろん、言語自体
がそういう表現をもっていれば、その表現を命令に変換することはできます。
しかし、それでは言語が特定のプロセッサアーキテクチャに依存することになっ
て、移植可能性に制限がでてきてしまいます。
そういったことを考えると、コンパイラはあまり複雑で多機能な命令はどうせ
使えないんだから、マイクロコード自身みたいな基礎的な命令だけあればいい
んじゃないか?ということになります。 RISC の基本的な考え方はそういうも
のでした。これにより、コンパイラは結局より効率が良いコードを出せるよう
になり、ハードウェアは単純になって性能が上がり、と2重に良いことがあっ
たわけです。
80年代の終わりから90年代の初めにかけては、これらの RISC プロセッサがそ
れまでの RISC ではないアーキテクチャのシステム、 インテルの 80386 やモ
トローラの68K 系、 DEC VAX、 IBM の 370 アーキテクチャといったものに比
べてクロック当りで高い性能をより小規模なハードウェアで実現し、さらにク
ロックも上げることに成功しました。その結果、 80386 以外の非 RISC プロ
セッサは、少なくとも汎用コンピュータ用としてはほぼ絶滅します。その中に
は日本の TRON プロジェクトで開発されたプロセッサもありました。
しかし、 RISC プロセッサが高い性能を出すようになった時期というのは、実
はその後の発展の方向が見えなくなった時期でもありました。浮動小数点演算
については、既に述べたように Intel が開発した RISC プロセッサ 80860 が
1 チップでほぼ完全な浮動小数点演算パイプラインを実現しました。整数演算
についてはもっと初期の RISC で完全なパイプライン化が実現されています。
そうなると、さらに沢山のトランジスタが使えるようになった時にどうすれば
いいか?という問題が生じるわけです。
そこでとられた開発方向の1つがスーパースカラでした。これは、要するに、
ハードウェアは2つとか4つとかそれ以上の命令を並列に実行できるように作る、
命令は順番に並べるけど、実行時に解析して実行できるものから実行し、可能
なら並列に実行できるものは並列に実行する、というものです。これは、とて
も大変な上に先がない技術で、例えば 4 個実行ユニットをつけても 1 つだけ
の単純な RISC に比べて 1.5-2倍くらいしか速くならないのですが、ハードウェ
アは4倍どころか 16倍くらいいる、という感じのものです。
もうひとつは、実行パイプラインを深くして(段数を増やして)クロック周波数
を上げる、というものです。 結局、 RISC であったプロセッサでもこういう
ことを一杯してどんどん複雑になることになりました。
さて、CISC は 80386 とその後継の 486 以外は殆ど絶滅した、というのは既
に述べたわけですが、これら x86 プロセッサは絶滅しませんでした。その理
由の1つは単純に MS-DOS や Windows はこれらのプロセッサでしか動かなかっ
た、ということでしょう。 もう1つは、これらのプロセッサは沢山作られたせ
いもあって非常に安価で、安い計算機というのは値段に比例以上に性能が落ち
ても売れるからです。そういうわけで、 386、486 と安いけれどあんまり速く
ないプロセッサ、という存在であったわけですが、 1993 年の Pentium から
話が変わってきます。浮動小数点演算に関する限り、完全パイプライン化した
演算ユニットを持ち当時のいくつかのスーパースカラ RISC プロセッサ、特に
SuperSPARC に比べてむしろ高い性能を発揮しましたし、整数演算でもスーパー
スカラを採用してそこそこ高い性能を実現したからです。これは、当初
0.6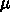 m のプロセスで 500万ものトランジスタを集積することで可能になっ
たものです。
m のプロセスで 500万ものトランジスタを集積することで可能になっ
たものです。
1995 年に投入された Pentium Pro、その改良版の Pentium II となると、もっ
とすさまじいことになります。これらは普通 P6 アーキテクチャと呼ばれます
が、P6 アーキテクチャでは x86 命令がそのまま実行されるのではなく、命令
がキャッシュから読み出された時点で RISC 風の命令に変換され、そのRISC
風の命令がスーパースカラな実行ユニットで実行される、という仕掛けになっ
たのです。これにより、同時期の多くのRISC プロセッサに匹敵する速度を、
しかしはるかに安価に実現したのです。しかも、1978年に投入された8086 と
相変わらず互換性をもったままでそれを実現したわけです。
この方式は、ある意味でマイクロプログラム方式の復活みたいなものですが、
変換されたマイクロプログラムがスーパースカラユニットで実行時に並列動作
することで、互換性を維持したままで高い性能を実現できるようになりました。
互換プロセッサメーカーであった AMD も K5, K6 といったプロセッサで同様
な方式を導入しました。歴史的には、最初にこの方式を導入したのは Nexgen
586 だったようで、この会社は次の Nx686 の開発中に AMD に吸収され、 AMD
は K6 の名前でこれを販売します。さらに、その開発チームが AMD K7
(Athlon) を完成させ、 Pentium Pro 系列の最終版である Pentium III を上
回る性能を発揮することになります。
この頃になると、半導体工場の建設も多額の費用を必要とするようになり、元々
半導体工場をもっていなかった Sun や MIPS はともかくとして、自分で工場
まで作っていた DEC や HP はプロセッサ開発を続けることが困難になります。
DEC は会社自体がなくなって Compaq に吸収され、その Compaq 自体が数年の
うちに今度は HP に吸収されることになりました。インテルは巨大な販売額を
背景に、半導体プロセスの進歩で他のマイクロプロセッサの1歩も2歩も先をい
くことになります。さらに、自社で論理設計から半導体製造までやっているこ
と、莫大な開発費をかけられることを生かして、他のマイクロプロセッサでは
困難な非常に高いクロックでの動作を実現します。
つまり、P6 アーキテクチャになって x86 の命令セットとスーパースカラな実
行ユニットが切り離された時点で、 RISC か CISC かという命令セットの違い
は殆ど意味をもたなくなり、実行性能は回路設計や半導体工場自体にかけられ
るお金で決まる、というのに近い状況になってきたわけです。
そうなると、生産量が少ない分開発費がかけられない x86 以外のプロセッサ
が死滅するのは時間の問題、ということになります。それをもっとも象徴的に
表しているのがインテル自身が開発してきた Itanium プロセッサでしょう。
Itanium は 1994 年頃からインテルと HP が共同開発してきた、 64ビット
VLIW プロセッサです。 VLIW (Very Long Instruction Word) は、 RISC をもっ
とも力任せに並列動作させようというもので、複数の実行ユニットに対する命
令を1つの「長い命令語」としてまとめて、それがクロック毎に投入される、
というものです。80年代終わりに Multiflow といった会社で開発されていま
した。一見よさそうにみえますが細かい技術的な問題が一杯あります。レジス
タファイルをどうするか、条件分岐命令をどうするか、機械語プログラムがや
たら長くなるのをどうするか、といったものです。 レジスタファイルの問題
は特に深刻で、実行ユニットが2つあってパイプライン動作できるためには、
演算だけを考えてもレジスタファイルから同時に4語読出して2語書ける必要が
あります。アクセスポートが6個いるわけです。メモリ転送命令もあるので必
要なレジスタファイルの能力はもっと増えます。また、結局同時に沢山アクセ
スされるので、トータルのレジスタファイルの語数も大きくないと効率がでま
せん。そうなると、ハードウェアのサイズは語数とアクセスポート数の積くら
いで大きくなる(実装によりますが最近はそういうのが多い)ので、実行ユニッ
ト数の2乗くらいに比例してレジスタファイルが大きくなってしまいます。
条件分岐も問題で、実行時に条件分岐を少なくするようなコンパイル手法など
が研究されています。
そういうわけで VLIW はなかなか上手くいかないのですが、インテルは x86
とは別に 64 ビット化した新しいアーキテクチャとして Itanium の開発を始
め、それに VLIW を採用したのです。 VLIW といっても Multiflow で開発さ
れていたような 7 命令とか 14 命令とかではなく、 3 命令にすぎないもので
した。
しかし、その開発は難航し、製品がでるころには自社の x86 プロセッサに価
格性能比で全く対抗できない、という状態が最初の製品の出荷を始めた 2001
年(当初は 1999年に出荷開始予定)からずっと続いています。
難航した一つの理由は、3命令では並列度が足りなくて、スーパースカラな実
行方式もとりいれることになった、ということでしょう。それではなんのため
に VLIW にしたのかわからないわけです。
結局、1つのプロセッサに使いきれないほどの沢山のトランジスタが1チップに
載るようになった時点で、命令セットの違いを実行時のコード変換で隠蔽する
ことが可能になり、その結果アーキテクチャの違いにあまり意味がなくなった、
というのが現状です。このため、沢山お金をかけて頑張って作ったところが勝
ち、みたいな状況になってしまっているのです。
スーパーコンピューティング、という観点から見ると、しかし、これはなんだ
かつじつまがあわない話になっています。単純な話として、1989 年の 80860
に比べて 2006年のマイクロプロセッサはトランジスタ数が 500倍なのに、演
算器の数は4倍にしかなっていないのは何故か?もうちょっと違う方法はない
のか?というのにあまり理解できる説明はないからです。
次章では、スーパーコンピューターではそもそもどんなことをしているのか、
という観点から、もう一度その辺りを検討することにしましょう。