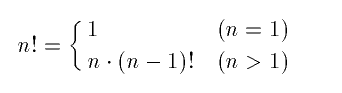
program recursion_sample(input, output);
var n : real;
function factrial(n :real): real;
begin
if n=1.0 then begin
factrial := 1.0;
end else begin
factrial := n*factrial(n-1);
end;
end;
begin
write('Enter n : ');
readln(n);
writeln('N = ', n:5, ' N! = ', factrial(n):20);
end.
上の例
は、階乗を計算するプログラムである。階乗は、下のように定義される:
Pascal のようなプログラミング言語では、この定義に従って素直にプログ
ラムを書くことができる。上の例では、まさに、
再帰を使うことで、角度、長さを変えて自分自身を呼び出すという形で簡潔に
アルゴリズムが表現できている。
配列のところ(前回)でやったソーティングについて考えてみる。
先週やった方法では、人間がやるとしたらとてもばかばかしくてできないような、手
際の悪い方法をつかっている。このために、手間がデータの数の2乗に比例し
て増える。これを、もう少しなんとかできないものだろうかというのがここで
の課題である。
例えばトランプのカードを人が揃えるとすれば、一つの方法は、まずハート、
スペードといった種類ごとに分け、それからその中を揃えることである。こう
すれば、枚数が減って扱いやすい。
もう一つの考え方は、まず揃ってない山を2つに分け、それぞれを揃える。そ
れからその2つを合体させるというものである。合体させるのは、両方の山を
みて順番が先なものをとっていけばいい。
どちらの方法でも、カードの山をいくつかに分けることで、手間を減らしてい
ることがわかる。ここで、よく考えてみると、例えば下の方法では、初めに2
つに分けた山のそれぞれを揃えるのに、さらにそれらを2つに分けるという方
法が使えることが分かる。上の方法でもおなじようなことができる。例えば、
7よりも大きいかどうかでさらに二つに分ける。
この、同じ方法を繰り返し使うというのが、「再帰」の考え方である。具体例
を見てみよう。
1. のところを行なうのが、手続き msort の前半部である。これは、
前半分と後ろ半分について、それぞれ msort 自身を呼ぶ。
2. のところは、手続き merge で行なわれる。ここでは、
dataの if1 から ie1 までと、 if2 か
ら ie2 までに入っている2つの部分列を、1つの列にまとめる。
この時、いったん wa という配列に書いておいて、終ったところで
書き戻す。
merge の動く様子
再帰という形に書くことで、高度な処理を単純な形に表現することがで
きる。これについては次週にもう少し詳しく学ぶことにする。
factrial(5)
→5*factrial(4)
→5*(4*factrial(3))
→5*(4*(3*factrial(2)))
→5*(4*(3*(2*factrial(1))))
→5*(4*(3*(2*1)))
→5*(4*(3*2))
→5*(4*6)
→5*24
→120
練習
お絵書き
再帰を使って複雑な図形を書いてみよう。
program tree_display(input, output);
#include <xgraph.h>
var gdriver, gmode : integer;
x,y,vx,vy : real;
i,j : integer;
procedure tree(n, x, y: integer; angle, length : real);
var x1, y1 : integer;
begin
if n > 0 then begin
setcolor( n mod 7 + 1);
x1 := round(x + length*cos(angle));
y1 := round(y - length*sin(angle));
line(x,y,x1,y1);
tree(n-1,x1,y1,angle + 0.25, length*0.7);
tree(n-1,x1,y1,angle - 0.25, length*0.7);
end;
end;
begin
initgraph(gdriver, gmode, '');
cleardevice;
clrscr;
tree(10, getmaxx div 2, getmaxy, pi/2, getmaxy div 4);
readln;
closegraph;
end.
これは、樹形図を書くプログラムである。原理は、指定した長さと角度で一本
線を引き、その先から角度をつけて2本線を引き、それぞれの端からまた角度
をつけて、、、というのを繰り返すだけである。練習
(ヒント:random(x) --- x は実数 --- という関数を呼ぶと、0 から x まで
の範囲の乱数 --- デタラメな数 --- を返す。これを使って枝分かれの長さ、
角度を変えて見よう)

ソート(2)
ここでは再帰を使って効率良く
ソートを行なう方法を考える。
program mergesort(input, output);
var n : integer;
data: array[1..100] of real;
wa : array[1..100] of real;
i,j : integer;
infile:text;
procedure merge(if1, ie1, if2, ie2:integer);
var i, j, k : integer;
begin
i := if1;
j := if1;
k := if2;
while (j <= ie1) or ( k <= ie2) do begin
if (j > ie1) or ((k <= ie2) and (data[k] < data[j])) then begin
wa[i] := data[k];
k := k + 1;
end else begin
wa[i] := data[j];
j := j + 1;
end;
i := i + 1;
end;
for i := if1 to ie2 do data[i] := wa[i];
end;
procedure msort(ifirst, iend:integer);
var i : integer;
begin
i := (ifirst + iend) div 2;
if ifirst < i then msort(ifirst, i);
if i+1 < iend then msort(i+1, iend);
merge(ifirst, i, i+1, iend);
end;
procedure print(n:integer);
var i : integer;
begin
for i:= 1 to n do begin
write(' ', data[i]:9:2);
if i mod 8 = 0 then writeln;
end;
if n mod 8 <> 0 then writeln;
end;
begin
n := 0;
while not eof(input) do begin
n := n +1;
readln(input, data[n]);
end;
writeln('Input data'); print(n);
msort(1,n);
writeln('Sorted data');print(n);
readln;
end.
このプログラムはかなり長いが、原理は比較的単純である。つまり、
つまり、上に述べた方法をそのままプログラムにしている。
教科書のマージソートのプログラムは、ちょっと高度でわかりにくいので、も
うすこしわかりやすくした(つもりの)ものを例にしてみた。
列a 1 3 4 8 9 列b 2 4 6 7 8 合併列 (空)
列a 3 4 8 9 列b 2 4 6 7 8 合併列 1
列a 3 4 8 9 列b 4 6 7 8 合併列 1 2
列a 4 8 9 列b 4 6 7 8 合併列 1 2 3
もちろん、「再帰」を使わずに、これまでに学んだ繰り返し文だけを使っ
て同じ処理をすることもできる。しかし、プログラムがかなり面倒でわ
かりにくいものになる。練習
なお、あるプログラムの実行時間を計るには time コマンドが使える。
time simple_sort < sample.dat
という風に入力すると、実行結果のあとにもう一行
0.040u 0.080s 0:00.56 21.4% 0+135k 2+0io 21pf+0w
というような出力が出てくる。この最初の数字が秒単位の実行時間である。な
お、実際にかかった時間はもっと長いことがあり得る。これは、ファイルの読
み書きの時間は正確には入らないこと、また何人かで1台の計算機を使ってい
るのでその分余計に時間がかかることによる。レポート
これまでの「練習」の中から、2つ以上を選んで解き、
をまとめて提出すること。ただし、2週前の2番は、それだけでは1問と認めな
い。なお、提出は、メイルで、いままでと同様に TA の近藤さんのアドレスに
Subject を kadai-3 として提出すること。グラフィックスの出力結
果を提出する場合には、xvを使って gif ファイルにし、ファイル名(サブディレクトリに置いた場合はそのディレクトリ名もつけて)をレポート中に書くこと。
可能であれば、レポート自体を HTML 形式で書き、文書の中に図へのリンクを埋め込むのでも構わない。
なお、今回のレポートは、適当な時期に WWW 上で公開するかもしれないので、公開さ
れても構わないような内容にすること。締切は、情報処理試験当日の、情報
処理棟の閉館時間とする。
次回予告
次回は、シミュレーション(時間発展する方程式の数値解を求める)の
手法について学ぶ。