つっても、非公開のを別につけているわけではない。
Copyright 1999- Jun Makino
2020/04 2020/03 2020/02 2020/01 もっと昔引用:伊達市が、原発事故のあとに測定した市民の被ばく線量のデータを、本人の同意を得ずに研究者に提供していた問題で、伊達市の須田市長は29日の会見で、個人情報の取り扱いなどが不適切だったとして陳謝しました。
引用:伊達市は、平成23年の8月から「ガラスバッジ」と呼ばれる線量計を市民に配って被ばく線量を測定し、データの分析を福島県立医科大学の研究者に依頼していましたが、その際、事前に同意を得ていない市民のデータも提供していたことがわかり、市は去年、調査委員会を設置し、経緯を調べていました。
引用:その報告書によりますと、同意を得ず提供されたデータは3万人あまりにのぼり、管理職の決裁を受けず、記録も残さない形で持ち出されていて、「行政の事務手続きや個人情報の取扱いとして不適切だった」と指摘しています。
引用:須田市長は29日の定例会見で、研究者とのやりとりなど関わった職員5人のうち、退職した職員を除く3人に再度、聞き取りを行い、必要と認められれば、処分を行う考えを明らかにしました。
報告書は 伊達市 被ばくデータ提供に関する調査委員会報告書についての これですね。
「データの分析を福島県立医科大学の研究者に依頼していましたが」とあるが、これどういう経緯かが?だが早野さんにもわたってるわね。
報告書には:平成 27 年2月 20日に外部被ばく線量測定業者から、直接、福 島県立医科大学放射線健康管理学講座助手(当時)の宮崎真氏(以下「宮崎氏」 という。)と元東京大学大学院理学系研究科教授の早野龍五氏(以下「早野氏」 という。)に提供されたデータ
続き (同年8月 12 日に匿名加工した可能性あり)
引用:専門家会議は速記業者を第2回のみ入れていたそうである(事実であろうか?) 2月25日に情報開示請求をしていた筆者に、第2回の速記業者の納品物が開示された。 司会進行と資料説明以外は、真っ黒で、委員の発言は全く消されていた。
3行まとめだけ引用しました。
公的かつ極めて重要な会議で議事録を残さないというのはよく分からないが、近代国家であることを放棄したいとかそういうことなのかしら?
まあ保存も公開もしたくないという主張はここでない色々なところからも聞こえてはくる。
あとまあ、実際にどんな議論がされようが事務方が(あらかじめ)まとめた通りに決まったことになったりするので、議事録は、、、みたいなところはあるが。
引用: テレワークでのコミュニケーションで最も多用するのがテキストチャットだ。メールよりもカジュアルなツールだけに、「はい」のような簡潔な表現にすると冷たい印象を与えるのだという。「意に反して怒っている印象を与えることもある」(吉田CTO)。
まあ普通に話をしてても「意に反して怒っている印象を与えることもある」気が。
animate パッケージを使うと(画像を1枚1枚epsにして)アニメーションを pdf にいれることができると。
animate の詳しい解説: The animate package
引用: 東京都は28日、新たに15人の新型コロナウイルス感染者が確認されたと発表した。 新規感染者が2桁となったのは3日連続。
連休あけたら出勤とかは連休中に比べたら増えるわけで、それでも抑えられるかどうかというところだったけど東京はやっぱり難しい?
宗教上の理由で iPad は使わないとすると何がいいのかっていうか、アン ドロイドのタブレットって絶滅危惧種? MediaPad 以外の選択枝なさそうなん だけど、 Huawei の Android 機を今買うのかという気が、、、
結局数値計算にしか意味がない AVX512 搭載したことでコアが巨大に なって電力も増えてるわけで。
引用: What we did was to take generics off the list for 202X but to immediately start work to make sure we had a proposal ready for the following revision, dubbed 202Y.
2030年代の Fortran ではテンプレートが使えるかもしれない!?
引用:ブーストモード(CPU動作クロック周波数2.2GHz) 倍精度理論最高値(64bit)537ペタフロップス
というわけで細かい性能数値公開されました。
A64fx のチューニングのおともにどうぞみたいな。
z=4 で 270km/s くらいで回る半径 4kpc くらいのディスク銀河を CII 輝線の観測で見つけたという話。z=4 で 4kpc なんだから軌道周期 100My 切るわけで、別に円盤になってもかまわない気がするが、、、
引用:国立大学法人化によって若手研究者を雇用できなくなったことについて、私には責任があります。あと何年生きるか分からないけれど、世界並みのレベルにするまで、徹底的にやりたいです。
雇用以前に、法人化したことで「官僚の天下り先」を始めとする要するに「理研」、、、でもあるんだけど「利権」になったことが問題であろう。
いや変な言葉使わないで。造語じゃなくて元からある言葉の意味を勝手にかえてるし。
まあもちろん乗算加算の同時実行とかあるけどそれくらい。
でもって、最近のスカラープロセッサだとどうかというと、アセンブラみ てもまだどう動くかわからない。演算レイテンシが大きいのにアーキテクチャ レジスタは少ないのでOOOがどれくらい働くかで性能が変わる。逆に OOOがちゃんと機能できるようにコード生成をしないといけない。
これは全てのデータがL1$ にあってもそう。もちろん、さらに L2$ とか LLC とか主記憶とかとの間をどうするかとかも考えないといけない。
OOOにしてもキャッシュにしてもハードウェアが勝手にやるので、それを アプリケーションプログラムの意図通りに制御するには試行錯誤が必要で、な おかつそもそも意図通りに動くとは限らない。
まあ、そういうことによって「それで性能だす」インダストリが成立する一方、計算科学としての内容の発展はアプリケーション開発のための資源(特に人的資源)が膨大に必要になるために大きなブレーキがかかる(かかっている)。
で、そういう複雑さは、例えば命令セットアーキテクチャの制限で物理レジスタが見えない、とか、キャッシュなので制御できない、といったなんとかいうか人工的に作られた制約によるもので、プロセッサというものがそうでないといけない、というわけじゃない。
というわけで、GRAPE-DR も GRPE-PFN2/MN-Core も、書いた通りに動くアーキテクチャになってるんだけど、逆に今の若い人は書いて動かしてみないと分からないものしか使ったことがないから難しいみたいなところがあるか、、、うーん。
というわけで兵庫県は解除。
引用: 大学等(大学・各種学校等) 十分な座席の間隔(できるだけ2mを目安に(最小1m))が確保されること。例えば四方を空けた席配置又は使用する座席の1/2以下とする措置などを行うこと。少人数で滞在時間が短くなるよう工夫すること
引用: 適切な換気が行われるとともに、学生・生徒の入れ替えのタイミングで消毒が行われること
これはつまり普通の教室での講義は当面リモートでということだわね、、、
SIR モデルの(パラメータ表示)解析解の論文。2014年なのですごい最近だ。御教示ありがとうございます。
引用:京の開発が始まった00年代後半当時、その1世代前のCPU(中央演算処理装置)の周波数は3ギガヘルツまでで設計していたのを、京では2ギガヘルツに落としました。
FX1 は 2.5GHz だったような、、、
引用:それを当時、富士通社長だった野副州旦さんから、「年間100億円の赤字だったら構わない」とゴーサインをもらい、社長プロジェクトとしてスタートしました。
引用:既存のビジネス向けサーバー事業が侵食されることを懸念した社内の幹部に露骨に妨害されたんです。「井上が勝手なことをやっている」と、私を完全に敵とみなして打ち落としに来ました。日本企業でイノベーションがいかに阻害されるかを私は身をもって経験しました。
引用:東日本大震災が発生した11年3月には、京は計算速度で世界一を取ることが間違いないスコアを得ていました。ところが、5月になって約100人いたCPUの開発部隊の部下をすべて取り上げられました。
引用:突然に呼び出されて、「君が考えていることは会社の方針と反する」と言われたのです。野副さんが辞任を迫られた時と同様、密室の出来事で反論しても無駄でした。
引用:そのころの私は手足をもがれた状態でしたね。富士通に残っていてもコンピューター開発のかじ取りはできないので、野副さんの勧めもあって、13年に理研に移りました。そこで「ポスト京」(京の後継コンピューター)の開発を担うことができればと考えたのです。
引用:ところが、富士通から理研への働きかけもあったようで、ポスト京のプロジェクトから外されてしまいました。
有料記事なのでまあ引用は適切な範囲でということでこの辺で。Fのサーバーはまだ SPARC だけど次はどうするんだろう?
東京の4月の実数がみえてる数の何倍だったかとかは超過死亡数のほうからしか明らかにならなさそうではある。とはいえ4月の緊急事態宣言とあと連休の効果があって今の数字まで減ったのは多分そうなのではないかと。
本当に5人とか10人なのか、実際には100人なのかは別にして、4月中頃から相対的にだいぶへってはいると。
で、問題はこれからどうやって再拡大を抑えつつ社会を動かすか、ということになるんだろう。
ヨーロッパは基本的に外出制限等を解除して、感染者増えたらまたきつくする、みたいな方向になりそうである。これは原理的に大変で、感染者増えだしたらまた数週間外出制限、みたいなことにならざるを得ない。
中国は普通に戻そうとしているがこれが上手くいくかどうかは?ではある。
原理的には、対策には外出制限みたいな大がかりな方法、頑張って主要な感染ルート見つけて対応する、という「クラスター対策」、とにかく感染した人を早期に見つけて隔離、みたいな方法がある、ということであろう。
この中でコストがちゃんと見積もれてそれほど大きくないのは最後の早期隔離で、それは例えば毎週全国民をPCRしても(複数人のサンプルをまとめるとかで件数1桁減るなら)1日100万件とかで、新しい機械を数百台いれれば計算上はできる。一人あたりのコストは数百円程度以下であろう。
あまりに brute force で、というならじゃあがんばって contact trace しますか?という話になるんであろう。まあ自粛と同じで、スマフォにソフトいれてないのは非国民、的な空気でなんとかみたいな。
閉鎖的なムラ社会って疫病には強いのかしら。
なんかメモリリークが多分 Zoom にあるかな?一度リブートしないと。
一応終わった、、、
N7 でこんなでかいダイ作るのか、、、FP64 で 19.5TFと。V100 の2倍? V100 3年前だから、ムーアの法則の終焉が明らかな感じではある。
TF32 という謎モードがあって FP64 の16倍、FP16 はさらにその2倍、あ、TF32 って仮数10ビットしかないのか。えーと、、、それ、、、××の××と××でみたいな。さすがそれを32と呼ぶのは詐欺じゃないですか?
引用:宮崎・早野論文には1年以上前から立ち入った批判がなされているのに著者からの学術的にかみあった応答がない。今後,早期に疑惑をはらす反論がなされるのかもしれない。そうあってほしい。そうでないとすれば,これは科学スキャンダルとしても際立ったものになる。
まあ早野さんとしては反論は(大学の調査委員会で「白」となった時点で)全てすんでいるのであとは沈黙してればいい、という考えであろう。
PCR 検査の数が日本ではふえないってまあその日本のバイオ研究はピペド依存だけど諸外国は自動化が進んでみたいな話なのかしら?今でもそうなの?
「今日の勉強会が皆さんの不安を払拭するため」といかいいおった。なんかみたいだ。
まあ田中さんが企画するからそうなるか。ということで Zoom ででませんかといわれたけど私は断わった。
田中さん「どう批判していいかわからない、作法ができてない」君 3.11 の時から何も批判してないじゃない?
まあ歴史は繰り返すという話だ。
30分くらいで理論と実装の話をとのこと。
github にスライドあるとのこと。まあこれみればいいか。
スライドの式に記号の定義がない、、、、
スライド4 i は infectedで、 A(t) はある人が感染してから時刻t後に感染させる人の数。
スライド22 をみると発見できてない分の補正の式が書いてあるけどこれはまだはいってないと書いてあるように見える。
じゃ駄目じゃん。話おしまい。
晩御飯にするか。
スライド20のFは、、、「報告の遅れ」の累積分布関数だそうです。
g(τ)は既知とするのか。 Nishiura et al. 2020 の serial interval とコンシステントになるようにとるよね?あ、ワイブル分布で 4.8日とのこと。
引用:東京都が発表している都内の新型コロナウイルスの感染者数について、保健所から多数の報告漏れなどが見つかっていることがわかった。都内の累計感染者数は10日時点で4868人だが、都は集計のやり直しを進めており、現時点で100人規模の漏れが見つかっているという。
うーん。
小人さんなのでドキュメントがない。とりあえずサイズ決めてデータファイル読んで線引くのは動く。
東京都(これは23区外も)の3月の COVID-19 による死者は9名。これが 10-30倍いても 統計とは矛盾しない。4月だと100人超えるので10倍とかになると有意に見える。
まあ少なくとも3月の東京では100倍多いとかいうことはなさそう、ということはいえる。
こんなの、ちゃんとした資料がでてくればすむ話だ。まあ資料の数学がわかる人がどれくらいいるかというのは問題なんだろうけど。
引用: SIR モデルをエコノミスト向けに解説したものに、Andrew G. Atkeson (中略)しかしながら、日本語で牧野淳一郎(神戸大学)によるさらに分かりやすい解説があり、本稿もそれにほぼ全面的に依っている。
ほめられた?
アブストラクトから引用: Results: We observed the first outbreak peak in Japan on April 3 for those infected on March 29 .Their R0 and q were estimated respectively as 2.048 and 99.987%.
引用続き: Discussion and Conclusion: By introducing a very high proportion of asymptomatic cases, two inconsistent phenomena might be resolved. This hypothesis should be verified through additional study.
q は無発症感染者の割合。これが 99.987% であば SIR モデルで現在の日本のデータを説明できるんだって。
いやこれさすがに駄目ではないかと思いますです。平時にちゃんとした研究ができるというのと、緊急事態に対応できるというのは違うということであろう。
まあだから、緊急事態にならないような仕組みが必要、というのがプロジェクト管理の教えるところではあるし彼らの本にも書いてあることではある。
でまあ普通の講義と同じくらい疲れる。
Zoom でできた講義の MP4 ファイル、105分で250MB だった。無駄にフルHDの解像度で手書きで一生懸命書いてこれくらい。音声だけだと50MBなのでまあそれなりにあるんだけど。
競プロとかでもいいのかも。ここでするか、みたいなのをみんなで鑑賞するの。
まあ多くの場合にする間違いがあまりにアレなので恥ずかしいというのはあるんだけど。
Zoom + G suites ではほぼ容量気にしなくてもよい感じだが、まあ、セキュリティは、、、私の意見としては Gである時点でどうせアレだし講義内容は別に全世界に公開しているし個人情報って私の字が下手なことくらいだ。
でも学生のレポート回収もGのほうかな?個人的には Mattermost になんかプラグインつけてやりたいが、学生向けは大学が提供してるものでないと。
なんだそれ?
ちょうど 2年前に書いてた。
コマンドラインオプションパーザとかなかったので公開はまだ。プロファ イラでみたら (perf 使った)計算量の8割以上が相互作用計算だったのでわりといい感じである。Ruby版(しつこいけど 2.5.1) の200倍速い。
Josh Barnes の C版と同等のはず。
AArch64 で Crystal 動く(かもしれない) のか。
C++ ネイティブのインターフェースなしにして C API 基本にすればバックエンド C++ でなくてもいいんだよな、、、いやしないけど。
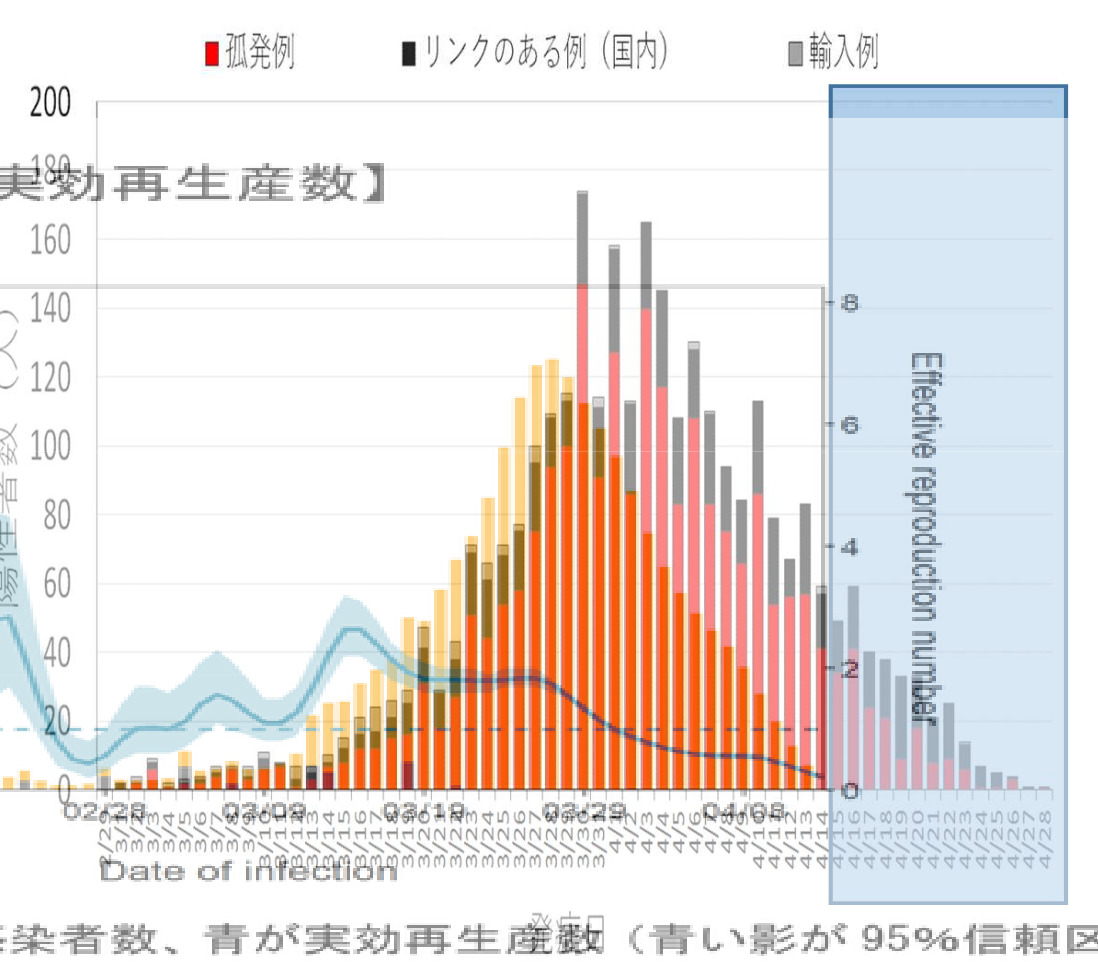
最初のページが「確定日別の感染者数」なんだけど、これが 東京都のサイトの陽性患者数と全然違う。
合計人数も違うし、4月中旬がすごく多くてそのあと減ったことになっている。何故違うのこれ?
5月になると、サイトのデータは165,159,91,87,58 なんだけど、資料のグラフは100を超える日がない。
あと、割と根本的な問題なのは、ここで提示されている実効再生産数のグラフが5/1の専門家会議見解にのってるのと全然違うこと。何やってんのかしら?
これ、一つの可能性は、現在に近づくほど発症日と検査日の間隔が大きくなっている、ということで、それを単純に発症日に反映させたらこうなった、というのである。
でも、そうだとすると、間隔が大きくなったのは何故か?が問題で、それは検査が間に合ってないからであろう。おそらくその効果をある程度取り入れた結果、5/1資料に比べて5/5資料では4月3日以降の感染者が大幅にふえたのではないかと想像される。
でも4月20日あたりから急にへっててこれは多分おかしい。
これ、後ろ向きの(陽性確定者数・発症日から感染日への)推定だけやってて、前向きの計算による誤差推定やってないのかしら?
20年前から自分のサイトに全講義資料がある私。でも Zoom のURLはここにはおけないし。メイルしとくか。
とりあえず明日何が起こるかだわね。
C++ 使うにしても、もうちょっと書きやすい言語ならこう書ける、というのを意識できるのは大事なことであるというのが一応一般論。
で、Crystal は速度的にも(Array の代わりに tuple つかうとか class の代わりに struct つかうとかちょっと注意すれば) C++ と変わらないので色々楽。あと静的型付け言語ってデバッグが楽な気が。
OpenMP 的なものはないけど並行動作の単位 である fiber が基本的に コア数に依存しない形で書けるから、あんまり面倒ではない。ただこれまだ デフォルトじゃないんだよな。 1.0 になる時にははいるだろうけど。
あとはちゃんとした P3T スキームの実装と、正則化と Slow KS と SPH と FDPS の利用と並列化くらいをいれたい。
Butcher tableau をテキストで与 えると係数テーブルに変換してジェネリックな陽的ルンゲクッタ関数に喰わせ る。とりあえず RKF8 までのテーブルつき。 こんなふうにつかう。
ここでは1変数だけど、多変数でも加算と Float との積が定義された型であればなんでも使えるはず。誤差評価はテーブルは入ってるがテストはまだしてない。
しかしこれで13段8次か。やっぱり 8次エルミートとかって強いね。
これちょっといじると Ruby で動く。手元の 2.5.1 だと Crystal の40倍くらい遅い。Crystal も Array 結構いじるコードなのでそんなに速くないんだけどまあ、みたいな。2.7 で JIT 使うのもやってみないと。
とすると Hard part の積分公式はなんでもいいわけで、スイッチ関数の 高階微分を機械的に生成する気があれば高次エルミート、それさぼるなら 陰的ガウスとか使うのが本当であろう。4段8次のガウスだって、3回で収束さ せれば陽的ルンゲクッタより速いし誤差項はずっと小さいはず。
正則化とどう組合せるかがまだ問題か、、、単純に、「今正則化しないといけない一番具合悪いやつ」だけ正則化してあとはしないとかかな。
もちろん、これはだから外出とか営業の停止等を解除していい、というわけではなくて、大都市以外では「現在以上に強化する必要はない」ということであろう。
逆にいうと、大都市では現在の状況ではまだ不十分「かもしれない」。ここで「かもしれない」なのは、特に東京で、検査人数に対して陽性率が非常に高いままであるために状況を把握するすべがないから。大阪もかなり怪しい。
言い換えると、日本での今後の対応のために第一に重要なのは、特に東京・大阪で一日、一秒でも速く、検査数を大幅に増やすことである。
もちろん、理論的には、現在の対応で実際に R が1 より十分小さくなっていて、本当の感染者数が減り始めている、という可能性もゼロではないが、そう判断するべき根拠はない。
一方、東京都や大阪府が迅速に対応することはあまり期待できない。大阪 府は4月下旬になって「新型コロナウイルスの感染確認の検査能力を2倍に強化 する」といっている段階であり、東京都にいたっては動きがあるかどうかも分からない。
一方、大学病院、医師会の動きは始まっており、 東京慈恵会医科大学 Team COVID-19 PCRセンターは安価に検査ができる体制をもっています。他にも多数の病院が独自に検査実施できる体制を整えているようである。
また、医師会の「PCR検査センター」も、報道によればすでに開設している。
おそらく、これらの検査を拡充していくこと、その情報を適切に集約していくことが現実的に可能な対応になるのではないか?
ヨーロッパでも国によっては倍くらい、それ以外だと最大10倍くらい、トータルの死者数増加から見積もれるCOVID-19による死者数と公式統計ででてくる数字の差があるという話。
東京はどうなってるかは気になるところではある。
とはいえこれだとニューヨークとかはピークアウトはしたのか?
そもそもいまどき eps に変換しているのが悪いか?今どき pngファイルを直接よめるはずだし。 15年くらい前に書いた latex 生成コードだからねこれ、、、
マクロなSIRとかじゃなくてミクロというか、個人をモデル化するようなことから対策ださないと駄目みたいな。伊藤君とこでやってるはずだけど。
伊藤君とこ コロナ濃厚接触者探して通知 理研スパコン富岳活用
引用:新型コロナウイルス対策のため、理化学研究所は開発途中のスーパーコンピューター「富岳」を前倒しして運用を始めた。
引用:理研計算科学研究センター(神戸市)の離散事象シミュレーション研究チームの伊藤伸泰チームリーダーは新型コロナウイルスの感染拡大対策の効果や、感染症がもたらす社会経済的影響の大きさを大学や民間と協力して調べ始めた。
うーん、ちょっと違うか。
Widespread PCR testing in the general population is unlikely to limit transmission more than contact- tracing and quarantine based on symptoms alone とサマリーには書いてあるんだけど、
本文の根拠は Widespread testing of symptomatic suspected COVID-19 cases in the community would support monitoring of the epidemic, but is unlikely to help reduce transmission since individuals with suspected COVID-19 are already advised to self-isolate.
というだけで、しかも別にモデル計算とかもしてなさそうであった。なにこれ?
要点は、一見指摘された問題点を理解しているようにみえるのに実際には明ら かに間違った解析結果になっており、全く信頼できないことには変わりがない、 ということになります。
引用:海外から「感染率さえわからない危うい国」と判断されている状況を、科学や医療を担当する記者たちは自分たちのデータ、自分たちの判断で、「おかしいだろ、それ」ともっと早い時期に明確に打ち出すべきだった。
引用:東電福島原発事故でも明らかになった、日本の科学医療分野におけるジャーナリズムの弱さが、再び、そっくりあらわれている。
まあそういう話で、明らかにおかしいことをおかしいと判断できる科学的・論理的検討能力がない、あるいはする気がない、あるいは判断できても報道する力がない、ということである。
まあそういうものだ。
ま、科学者(と今回医療関係者)のほうの問題が大きいと思うけど。
神戸市民病院+神戸大学(岩田先生他)の論文。専門家として信頼が置ける人達の論文といっていいのではないかと。
市民病院にきた1000人に IgG 抗体検査して33人が陽性であり、これが神戸市民のサンプルだとすると神戸市には5万人の陽性者がいることになる、とアブストラクトに書いてある。
内容についての文句は私じゃなくて岩田先生にいって下さいな。サンプルにバイアスがあるとか色々。
しかし現実には積極的検査で収束させることが可能であるとすると、割と安直な説明は、無症状感染者は周りに感染させる能力が低い(Rが小さい)ということであろう。症状がでると前後がもっとも感染力が高い、という研究結果もあるわけで、無症状ならあんまり感染させないというのはありそうな話である。
そうすると、抗体保持者の数よりずっと少なくても検査+隔離が有効に働く、というのも理解できなくはないのかもしれない。
単純なモデルとしては、 I を2つにわけて、βが2x2行列だけど自由度は3とか。
引用: 中国のハイテク企業に対するアメリカ政府の制裁が続くなか、スーパーコンピューターや高性能サーバーの開発を手がける国策ハイテク企業、曙光信息産業(中科曙光。英語名はSugon)は国産CPU(中央演算処理装置)の採用拡大に乗り出す。
引用:新開発するワークステーションやサーバーにはX86、MIPS、ARMの3種類のアーキテクチャーを採用する。
引用:そのうち市場の主流を占めるX86はアメリカのインテルが開発したもので、国産半導体メーカーでは中科曙光の子会社の海光信息技術や上海市政府系の兆芯集成電路などが互換CPUを開発している。
引用:中国のあるクラウドサービスプロバイダーの関係者によれば、米中関係の緊張が続くなか、国産CPUの振興は必然の流れだという。しかし主流のX86アーキテクチャーで、国産CPUとインテル製には今も歴然とした性能差がある。
Alpha はないですか、、、
{kind=link}