つっても、非公開のを別につけているわけではない。
Copyright 1999- Jun Makino
2023/05 2023/04 2023/03 2023/02 2023/01 ---- もっと昔それはともかく、「沖縄県立中部病院でコロナ診療に当たる医師、高山義浩 さんに聞きました。」
「はい、厚労省のアドバイザリーボードでも、沖縄は減衰振動(流行を繰 り返しながらも規模を小さくすること)に入ったのではないかとの指摘があり、 いわゆる「集団免疫効果」が認められるのではと期待していました。」
「減衰振動」という言葉の使いかたがおかしい。減衰振動って普通の用語 としては振幅が減る(線型なら固有値の実部が負)というだけで値が0にいくこ とではない。
SIRS だと通常の意味で減衰振動的で、時間がたつと新規感染者数は一定 値になる。
で、実際、そうなるのがありそうな話で、図 https://d2fuek8fvjoyvv.cloudfront.net/naokoiwanaga.theletter.jp/uploadfile/35f349e3-da72-48a4-9e18-cf287c8ac45d-1687931357.jpg みても死亡者数でみるとどの国もあんまり減ってない。
つまり、新規陽性者数はどの国もまともに数えなくなった、というだけで ある。
というか、コロナ4年目の今になって「いわゆる「集団免疫効果」が認められるのではと期待していました。」ってさすがに専門家としていかんのでは?
SF3 は 5nm に比べて「消費電力50%削減又は動作周波数30%向上が期待でき、エリア面積は35%削減」
SF2 が 5nm に比べて電力効率が 2.7倍なのは素晴らしいがトランジスタ 密度は 1.6倍か、、、まあ TSMC でも N2/N3E のトランジスタ密度向上はやっ ぱり小さいのであんまり変わらない。
SMBH 合体がいつどれくらい起こってるかとかの研究が一杯必要になりそう。
先々週から先週はちょっと減ったのでピークが近いかと期待したがそんな ことはなくて増えた。 モデルナだと順調に増えてるのでまだまだ増えるのかな。
〆切だいぶすぎた何かを半分処理してから講義準備。一応終わったかな?
ここの「告示濃度比総和別(推定)貯蔵量」 2023年3月31日現在では 「ALPS処理水」は 418,500m^3、全体の35%。
なので、1年半で 8400m^3ふえたと。年間 6000m^3 くらいで処理していることになる。
一方、全体の合計量はどういうわけか1215200 から 1211900 に 3300m^2 減っている。これどこに消えたのかしら?
とりあえず、今の ALPS の処理速度では全部処理終わるのは100年以上先なんだから、放出考えるのはそれからでいいんじゃないのという気が。今放出したいのは何故なんだっけ?
2018年10月1日の 東京電力ホールディングス株式会社 福島第一廃炉推進カンパニー 多核種除去設備等処理水の性状についてだと、
「ALPS処理水」相当は 136,700m^3、残り(まだ放出できる濃度になってない)は750,100。で、2023年3 月には残りが 793,400 になって増えてる。
つまり、運転実績としてはALPS処理は汚染水の増加に追い付いてない。
21年の記事 処理水タンク「23年春に満杯」は苦しい主張? 後ずれの試算でも海洋放出へ突き進む東電 -- 要するにタンク増設しないと一杯だから海洋放出したいと。増設すればいいのではとしかいいようがないよねこれ。
でもこれなかなか危険な方向で、 Intel がおちいっているジレンマには まらないか?的。
というか、「GP」GPU なのに何故というか本当に速いCPUって必要なの? という疑問はある。まあ、 Cuda で全部書きたいかというと嫌なんだけど、 これは言い換えるとそういう問題であってハードウェアの問題では本来ない。
まあ、メモリ構成の問題はあって、データが全部はじめから最後まで GPGPU の側にあるのでないと速い CPU が必要になっちゃう。
CM なんかはもちろんホストの VAX が CM のメモリに直接読み書きできた。 なので、そっちに宣言した変数も普通に C とか Fortranのプログラムでアク セスできてた。
SC2 の MIPS コアとかはそうなってるはずで、それがあれば、あと適切な プログラミング環境があればほとんど全てをアクセラレータ側で実行できる。
まあここで適切なプログラミング環境ってOpenCL でもCuda でもなさそうというのは問題ではある。
それでも HPF でいいじゃんという話はある。まあ OpenACC でも。 OpenMP offload はそういうわけでそもそも offload じゃないのでちょっとず れる。
ただ、実装を考えると例えばPE間通信でしたいことと OpenACC とかで表 現できることの間に semantic gap はどうしてもある。
つまり、 data parallel 的に書いたものからそのままコード生成すると、 高いメモリバンド幅を要求するコードがでちゃう。
原理的には、 Formura で要請するみたいな差分スキームだけ書くとか だとそこからブロッキングするコード生成とかはできるけど、それは完全 に DSL。
まあ HPF というか OpenACC 的な書き方と OpenCL 的な書き方が共存できればいいのかも?
別に関数とか excel 互換とかじゃなくて、Emacs Lisp の関数がそのまま書けると。
グラフ見ると 2022年はそれまでのトレンドからも今後の予測からもずれててすごい。
福祉の(実質的)公平性は重要だと思うけどそれとは研究費は別の話ではないかという気も。研究開発費はものすごい額が流れるところには流れてるわけで、そっちからちょっとのほうが現実的。
まあこのあとはアメリカも ASCI 計画の混迷の時代にはいるわけではある。
、一つは SPR 側で AMX とか演算機能強化してい るのが Ponte Vecchio と組合せると全く無駄になること、もうひとつは Ponte Vecchio のアーキテクチャが相変わらず x86 に引っ張られていて 電力性能とか実行効率が??なところである。
まあ、ここ30年くらいのスパコンの死に方の基本は物理共有メモリアー キテクチャで並列度の限界にきて死ぬ、というもので、システムレベル だと Cray C90、ノードレベルだと Red 以外の全部の ASCI マシン。
今はチップレベルで物理共有メモリが無理になっててどうしましょう?という 時代ではある。 Aurora もその流れの中にはある。
で、その URL で PC というか Ubuntu の Firefox でアクセスして、 まずはパスワードを変更しろというのがでる。これはまあよい。
が、初期パスワードはこう、というのが画面にでるののはクソである。
で、パスワードに特に文字数とか使える文字に制限があります、という注 意書きがなかったので12文字でアルファベット大小、数字、記号がはいったの をいれたら、
以下のメッセージがでた。 「パスワードの強度が足りません。文字の種類は、半角数字・半角英大文字・半角英小文字を入力し、長さは8桁以上、10桁以下での設定をお願いします。」 これ作った会社は滅びるべきである。
さらに、契約内容の PDF のリンクをクリックしたら サーバ エラー(HTTP 500) サーバエラーが発生しました。 申し訳ございませんが、再度ログインしてください。 それでも解決しない場合は弊社サポート窓口へご相談下さい。 とのこと。
これ、どうもスマフォからしかダウンロードできない模様。 これ作った会社は滅びるべきである。
で、圧力は 3e7N/m。 1t の水をこの圧力で加速すると加速度が 3e4m/s^2で、1cm 動くまでの時間は 3e4t^2 = 1e-2 なのでだいたい 1ms。 10m/s 程度までしか加速されない。
これは1次元ショックチューブ的な、ある瞬間まで壁があってそれが全部一瞬でなくなった時の1次元の速度はどうなるかという話。ちょっと膨張すると圧力が0になっちゃうので、あんまり速度が上がらない。
もちろん、小さい穴があいたとかだと、そこからでる水は非常に高速にな りえる。でもそれは定常状態では、の話で、穴があいた瞬間から速いわけでは ないはず。
1次元問題にすると音波みたいなものが伝わってくだけでもどってこない ので、あんまり加速できないのはあってるかも。3次元球対称とかだと音波は 減衰するのでちょっと広がると圧力0でなくなって、加速時間が伸びそうな気 が。
問題: ○○に適切な単語を入れよ。(××と△△はユニークじゃないので)あと文字数は2でなくてもよい。
労組とか、いきなり弁護士にとかのほうが結局いいんだろう。
これプリフェッチでなんとかなるものではないんだっけ? ハードウェアプリフェッチが機能してないとか?
GRAPE みたいな専用計算機であれば、もちろんはじめからアプリケーショ ンの全部ではなくて演算量のほとんどではあるけどコードのごく一部だけを実 行するので、残りを実行する何かは必要である。
でも、GPU なら一応プログラマブルなわけで、原理的にはアプリケーショ ンの全部をそっちで動かせるはずだし、NVIDIA GPU の原型といえる MasPar とか CM はもちろんそうなっている。
MasPar とか CM のプログラミングモデルは「データ並列」で、要するに大抵の大規模 な計算って沢山のデータに対して同じように操作するよね?だからそう書くの がいいよね?というものである。
データ間で並列化できなさそうな操作というのも大抵全部できる、 というのは私がいまさらいうまでもなく Hillis and Steele 1986に全部書いてある。
あと Programming a highly parallel computer こういうのもある。Hillis and Barnes 1987。Barnes は Josh で BH tree の Barnes である。
もちろん、歴史的にはデータ並列言語が想定したマシンモデルである大規 模SIMD超並列は、プロセッサ・DRAM間のデータ転送が計算速度に追い付かなく なったところで絶滅して、TMC は chapter 11 したし MasPar も消滅した。
で、GPU はそこどうしたかというとメモリバンド幅が絶対的に不足なのは 諦めて、山のようにレジスタ用意することである程度のバンド幅の節約(レジ スタ再利用)とレイテンシ隠蔽を実現した。
んだけど、それで十分だったかというともちろんそうじゃなくて、結局 深層学習みたいに結構でかい行列積がでてきて必要メモリバンド幅がすごく少 ないものでないと性能はでない。
まあでも、その辺そんなに性能でなくてもかまわない、ということもある わけで、プログラム書けるなら全部 GPU側でもいいはずである。
でもそうなってないのは、一つは GPU 側のメモリが小さいからである。
PEZY なんかはその辺逆で、 SC 側にしかでかいメモリがなくてホストは (特に SC2では)貧弱だったりしたので、あらゆることを SC2 でせざるを得な いところがあったし実際できた。
(まあT先生とかN先生とかY先生の超人が頑張れば、という条件がつく気もするがそれはそれ)
ノード間通信にCPU、というのはあるかもしれないけど、逆にこれは smart NIC にオフロードみたいな話になってるわけで、送るデータ用意するとか 受け取ったデータ分配するとこかは別に CPU でなくてもできる。
まあ、MN-Core の場合にはそもそも命令列を生成・供給するものはいるわ けで、それを柔軟に実現しようと思うとそこそこ強力なプロセッサは必要では ある。でもまあ、そこも CM みたいにある程度のデコードをハードウェアロジッ クでやればそんなに大したことはない。
結局、CM の時代と違うのは、DRAM がすごく遅いこと、その代わりにそこ そこ速い SRAM が少しはあること(少しといっても CM の頃のDRAMくらいはあ る)で、それ向けのプログラミングモデルはなんでしょう?という話か。
つまり、データ並列では駄目なんだけどじゃあ何?と
一つの回答はもちろん ONNX で、「プログラム」ではなくてそれが実現し たいネットワークを与えればよかろうと。深層学習ならこれでよい。
他に対してデータ並列言語とかでいいのか、なんかもっとましなものがあ るべきか、が問題だけど、おそらくそれは2階層でデータ並列環境の上に アプリケーション向けというかドメイン向け環境を構築する、ということ かなあ。
データが超並列側にあるなら、従来の HPC アプリケーションを、という 話に対してはFortran 2008 コンパイラありますでいいような気が。まあつま り CM-Fortran である。
若干バブルな気もするが、今までできなかったいろんなことが実際にできつつある、というのと、滅茶苦茶計算パワーいる、というのはまあわりと間違いないよね、、、
私が憶えてるのは、物性研にはいった PC-2 は安定はしてなかったけどメ モリが大きかったので他ではできない計算ができて良かったと浅野 摂郎さんがいっ てたことくらいである。
浅野さんは私が駒場から本郷に移動した時に駒場の学部長で、人事異動を 教授会で報告する時に「研究費が減って大変残念」みたいなことをいったとい う話を私は人から聞いたということは教授会さぼってたのかな?
ただこれ、gzip で圧縮した大きなファイルだとメモリに全部展開して解凍してからファイルに書くのかな?
元々は KNH で 2018年頃で 180-450PF とかいってたよね、、、
あれ、Compute TileはTSMC N5だっけ?
NVIDIA のGPGPU の理念は Scalable Parallel Programming with CUDA: Is CUDA the parallel programming model that application developers have been waiting for? にあるところであろう。
これ見ると、要するに Cuda thread というのは Connection Machine の virtual processor が MasPar を通って GPGPU に持ち込まれたものだという ことがわかる。
CM の仮想プロセッサは、 要するに SMT で、時分割で1つの プロセッサが多数のプロセッサのように振舞う。CM の場合には DRAM 主記憶が論理的には各プロセッサに直結で、これも 仮想プロセッサの数で分割される。
仮想プロセッサの目的はなんだったかというと、要するに データ並列なプログラムを自然に書くことだった。物理プロセッサが 64k 個で例えば 128^3 の3次元計算だと、1PE が 4x4x2 の格子を 分担する。
32個の仮想プロセッサに分割すればアプリケーション プログラマーは「格子点1つ」のプログラムを書けばよくてループ構造は 不要となる。
「隣の格子点のデータのアクセス」は全部プロセッサ間通信で表現される けど、実プロセッサが同じもの同士の通信は単なるメモリアクセスなわけで そういうマイクロコードを実行すればよい。
で、Cuda スレッドでなにができたかというと、第一義的には主記憶レイ テンシの隠蔽であろう。多数のスレッドがメモリアクセスするので、レイテン シが大きくてもバンド幅があればいい。
この辺は Tera MTA (Cray XMT) とかも類似のアイディア。但し、こっち は真面目にマルチスレッドだけど Cuda thread は本質的にベクトル命令である。
で、NVIDIA GPU では、巨大なレジスタファイルを用意してこれをスレッ ドで分割する、という方法をとった。まあ、SMT ならスレッド毎にレジスタ持 つしかないわけでこれはこれで当然ではある。
但し、その結果古典的なベクトルプロセッサと同様に、Cuda で 自然に書くとレイテンシは隠蔽できるがメモリバンド幅は一杯使う プログラムになってしまう。
もちろん、多数のレジスタを使うことで ある程度データ再利用ができないわけではないが、そもそも 全格子点に対するデータ並列プログラミングになってしまってるので、 キャッシュブロッキングとか不可能である。
キャッシュブロッキングのためには、折角仮想プロセッサというか スレッド機能があるのに、それを元のデータ全体には使わないで キャッシュにはいる領域にしてループ回すようなコーディングが 必要で、これは人類には困難である。
密行列乗算とかならそれでもなんとかしているわけではある。
なので、GPGPU アーキテクチャと普通の階層キャッシュを組み合わせると、 LLC がものすごく大きくないとあんまり性能向上に貢献しない。まあ、だから、 A100, H100 は巨大な L2 をもつようになっている。
但し、この L2 はバンド幅があんまり大きくない、これは、共有キャッシュ で物理的に SM から距離があるので、電力制約からバンド幅を大きくできない ためである。
なので、行列乗算とかならそれでもなんとかなるけど、例えば陽的差分法 とかで既に上手くいかなくなる。
で、ハードウェアレベルでどうすればいいかはもうわかっていて、 Sunway、 PEZY、あるいは MN-Core のようにプロセッサコア毎にローカルメモ リをつけることである。
ソフトウェアとしては、多数のスレッドは止めにして実行されるプログラ ムはハードウェアサイズを意識し、ローカルメモリに必要なデータロードして 計算全部やってから書き戻す、というようなことを明示的にやる必要がある。
アプリケーションプログラマーがいちいちそんなことをするのは阿呆らし いので、DSL は必須、ということにはなる。まあ深層学習は既にそうだしみた いな。
あと、ローカルメモリ小さいので、非常に高速な同期や縮約演算が必須に なる。 Sunway はレジスタ間通信があってわりとよい。MN-Core は SIMD なの で同期不要なのが並列化効率の向上には非常に有効である。
もちろん深層学習では結局計算量が大きいのは行列行列積だけなので DSL が上手くいくというところはある。
で、これでじゃあ次の10年いいか?というと、そろそろ駄目である。
Sunway は 2014年だし PEZY もその辺で、15年たつとハードウェアの境界 条件が大きく変わる。
どう変わるかというと、 28nm とか 16FF から N2 とか N1.4 になって 演算の電力性能は30倍くらいになる。これは、データがチップ内部を水平に動 く距離を 1/8 くらい(電圧が 1/2として)にしないといけない、ということで ある。
要するに、DRAM が普通にオフチップではだめだし、 2.5D 実装でも駄 目、そもそも LLC というのが物理的に無理、ということである。
つまり、LLC からローカルメモリに移動したのと同じように、DRAM も物 理的にプロセッサコアに近付ける必要がある。まあ要するに 2.5D では駄目で 3D集積が必須というだけの話である。
簡単にいいとも悪いともいえない話ではある。
ちなみに Lia が大学院生のころは(ギリシャの話)計算機を冷やす水を学 生が運んでたといっていたがこれは本当か嘘か知らない。
で、TSMC がN4X とか N3X とかの高電圧向けプロセス最適化をやってるのはそういうわけであると。
私の感覚では、1Vで最大レチクルのチップを N4 とか N3で作ってそれで回るような クロックで回して電源供給とか冷却って到底無理なんだけど、GPU でもダーク シリコンはまだまだ多いということか。
ただなんとなく納得がいかないのは、 1V とかの(私の感覚では)狂気の電 圧かけてるならそれでクロック 2GHz もいかないのはなんかおかしい、私には わかってない謎なクリティカルパスがあってクロック上がらないんだろうか?
というか 1V はやっぱりなくて 0.8V くらいかなあ。 暗号通貨業界は 0.4V が当たり前で、これはそれでも電気代がでかいということである。
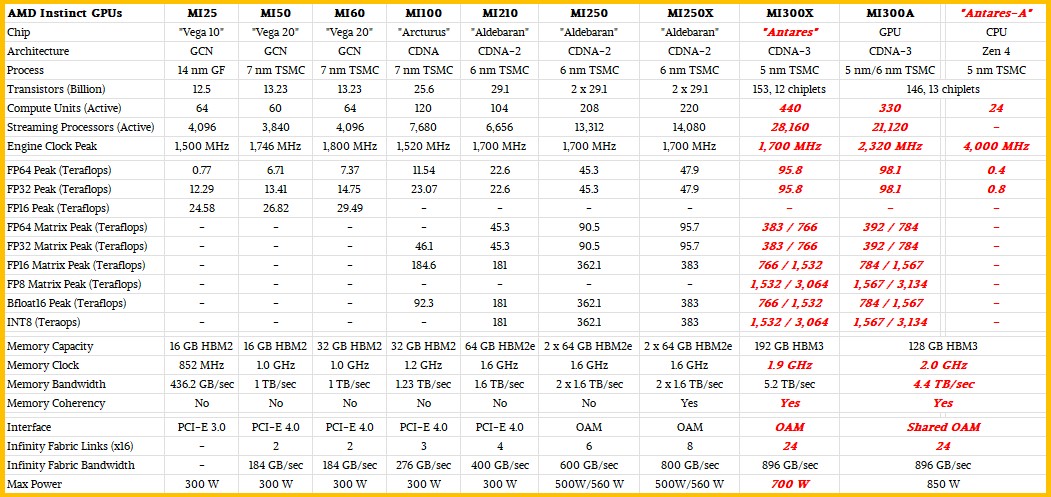
H100 は結局、、、今の WP では SXM5 で 66.9TF、576 Tensor Cores/GPU。 White Paper の絵だと、H100 Tensor core は FP16 で 4x8x16x4 FMA で 4096 演算にみえる。 でもこれでは計算あわない。
H100 の boost clock は資料によって書いてあることがみんな違う。 1.8GHz で、この時に FP16 1Pflops とすると Tensor core あたりの FMA の数は 512 = 4x8x16。演算数で 1024。FP64 では64。 FP64 の総演算数は 36864。
この数値は FP64 コア数 8448 の4倍で、Tensor Core の FP64 性能がそ うでない時の2倍と整合的である。FMA としては 18K個 なわけで、FMAあたり10 万トランジスタが組合せ論理として必要とすると 1.8G トランジスタ。
トランジスタ総数は 80G とあるので、総トランジスタのうち演算器の組 合せ論理にいってるのは 2.3%。これは少ないようにみえるかもしれないが非 常に高くて、 PEZY-SC 並み。A100 は 1.7%、A64fx は 1.3%である。
まあ、なので、ハードウェアとして面積あたりの性能あげるためには、 この 2.3% を 10%とかそれ以上にもっていくことが第一、次は低電圧で 高クロックを実現する深いパイプライン構成(某社CPUみたいな)ということに なる。
アクセラレータでは深いパイプラインは CPU と違って必ずしも効率低下 要因にならないので。
というか この性能(赤いとこ)でるはずないよね?なんだろこれ?
行列乗算だからといって 700W で FP64 で766TF なんか絶対でるはずがな いので、まあ MI250X の2倍ちょっと、FP16 もやはり2倍ちょっとではないだ ろうか?
表の赤い数字はAMD公式ではなくて、要するにAMDはFP性能について語っていない。
MI250X の AMD公式の数値。これも FP64 95.7TF がでることがあるのかどうか不明。
H100 の性能も謎で、NVIDIA のページに FP16 1979/1513(SXM/PCIe)と書いてあるのが本当なら 3-4EFになりそうなものである。
言い方を変えると、消費電力が2倍で性能が同じでも、値段が 2/3 なら そっちのほうがいい。 800W が 1.6KW になっても、500万が350万になれば いいわけだから。
これは、シリコンの面積あたりの価格がすごく高くなったからこういう話 になる。まあ、ではどういう設計にするべきかというと、面積あたりの性能 が最重要なので、トランジスタのうち演算器に使っている割合をあげること と、高クロックのため深いパイプラインにすることが重要になる。
まあ、大雑把にいって調達コストと電気代が釣り合う辺りが最適。
例えば電圧とクロックが比例するとすると最適なクロックは決まるんだろ うか? ダイコストで規格化するとして電圧を V とするとトータルコストは 1+V^3, 処理能力は V。なので、処理能力あたりのコストが最小になるのは 1/V + V^2 が極小で、V^3 = 1/2。
つまり、ライフサイクルでの電力コストがハードウェアコストの半分のと ころが最適解である。
一般にクロックが電圧のα乗とすれば トータルコストは 1+V^2+α, 処理能力は V^α。なので、処理能力あたりのコストが最小になるのは 1/V^α + V^2 が極小で、V^2+α = α/2。
まあ基本的にはより安全規制が厳しくなってその対応でどんどんコストが上がるという話ではある。TMI以降ずーっとそう。
なので、60年運用というのは要するに新しい、もうちょっと安全なはずの原発はコスト的に不可能なので古い危険なのを運用しようという話でなかなか狂気の沙汰である。
自分の首をしめるのはまあしょうがないんだけど事故で周りを巻き添えにするのは勘弁して欲しいという気はする。
96コアの 9654 と 128コアの 9754 を比べるとブーストクロックが 3.7GHz から 3.1GHz にさがってるので最大クロックで動いた時の性能は 12% しか上がらないことになる。まあ電力上限同じだしそんな感じ?
さくらが構築というのはよい方向な気が。Sさん(どっちの?)が死にそうではある。
で、これに実際にどれだかかかったかはよくわからないんだけど、V100 1 ノード300年相当とか書いてあるものが多い。 FP16 で120TFなので300年の演算数は 1.1E24。そうすると 30% くらいの素晴 らしい実行効率がでていることになる。本当?
V100 でこれだけ実行効率でるなら B/F 少なくとも V100 以上にはいらな いわけで、、、
私の意見としては、今の LSI 開発で一番駄目なのは大規模シミュレーション技術で、でかいチップ作ってもRTLレベルでもゲートレベルでもシミュレータって1ノードでしか動かない(分散メモリ並列ができてない)。
P&R とか DRC とかも全部そう。この辺なんとかしないとロジック設計はどうにもならない。
「滑り台は重い人が速い」という物理法則との矛盾の謎を立教大の学生が調査 -- こちらはプレスリリースを記事にしただけ。
「物理教育」になんか投稿するべきかもしれないけど会員の投稿しか受け付けないそうなのでパス。会費はらってまでなんかすることもなかろう。
今までスプリッタもってなかったのでノートPCをタブレットにつなぐとプロジェクタに出力できなかったんだけど、スプリッタ導入したからできるはず。多分。 今までは Zoom に別のノートというか Surface Go つないでそっちの画面をプロジェクタにだしてた。
(IV)多数の演算器が1チップにはいるようになった時代 にわけられる、と いう話は10年くらい前からしている。で、そうすると、もちろん (IV) の時期 のチップ内並列アーキテクチャは (II)の時期のシステム内並列アーキテクチャ をなぞる。
で、(II) はプロセッサ内並列演算器のプロセッサの共有メモリ並列、つ まり parallel vector processor で、Cray X-MP から T-90 まで、 日本では VP-200 から 日立 S-3800あたりまでである。
この先はどうなったのかというと、富士通は分散メモリの VPP500に、NEC は小規模な共有メモリシステムを複数組合せたマルチノードに、日立は ベクトルやめて分散メモリマイクロプロセッサ超並列に。
Cray は製品として意味があっ たのは T3Dだけとするなら分散メモリマイクロプロセッサ超並列になった。
なぜ分散メモリにならざるを得ないかというと、演算性能に対して必要な メモリバンド幅をシステムワイドな物理共有メモリで実現することが不可能 になったからである。
半導体技術が進んで演算器の数が増えても、配線で データ送る電力はそんなにさがらない。
そうすると、共有メモリベクトルプロセッサと同様な進化をしてきた共有 メモリメニーコアプロセッサにも同じ問題が起こるわけで、実際におこってい る。これの解決は、分散メモリにすることであるのはわりと明らかである。
とはいえ、共有メモリベクトルプロセッサと違うところは、主記憶は チップ外にあって、分散メモリにしてもメモリバンド幅を回復できない、と いうところであった。これは HBM とかでも同じで、 DDRx よりちょっとまし だけど焼け石に水である。
つまり、チップ(あるいはパッケージ)内分散メモリアーキテクチャに進む ためには主記憶がオンチップにならないといけない。逆にそうなれば問題は本当 に解決される。
まあ、これは、なのでプロセッサダイと DRAM ダイを積層するのは極めて 重要、という話。アクセラレータよりむしろ汎用プロセッサでこっちにいって ないといけない。
でも、現在のメニーコアプロセッサが末期の共有メモリベクトルプロセッ サみたいなある意味進化の行き止まりにきちゃってて、そこからどこにいけば いいのかわからない、というのが現状にみえる。というかそこに解決があって も見えないみたいな。
これは GPU も同じ。まあ、Intel なんかだと GPU のはずのもの も CPU と同じように作るので初めから死んでいる。
まあ、そういうものだし、なのでアーキテクチャの世代交代は企業の交代 を伴うわけである。クーンが書いてたパラダイムの交代は研究者の死滅で起こ るというのと同じだが企業は製品が売れなければ死んでしまうのが違いである。
これが本当だと、 1コアFP32 16GF、1チップ FP32 16TF/20W で大変素 晴らしい性能。
Esperanto Works to Fill the Software Gap for RISC-V AI Servers 性能の数値はピークで 100-200Tops、電力は20Wと書いてあるけど、、、
N7で 570mmsq もあって 20W しか使わないのはなんかそれいいのか?という気が。 チップの値段のほうがライフタイムの電気代よりはるかに大きそう。
高い HBM3一杯つけてることや色々な冗長性をいれてるにしてもチップ面積に 対して線形以上に価格あがること、さらに製造数の違いも考えると結構 H100 安くない?
まあカードとシステムで違うとはいえ M2 Ultra もコストの大半がCPUだろうし。H100 高いんだけど、それはダイが高いからで NVIDIA が暴利とってるからじゃないみたいな。
まあ、Ultra じゃないただの M2 (155mmsq, 20b trs) だと16万円なんだよな、、、
記事にも URL がありますが牧野への取材のきっかけになった ローラー式滑り台の力学。 そういえば首縊りの力学的タイトルである。
富岳だと 12threads/process で動くんだけど x86 だと 4 threads/process だととまる。なんだろこれ?
あと、以下の改良をしようという話になってはいる:粒子毎に半径、密度を指定する。現在は質量は変えられるんだけど半径(物理的に衝突する時の)は同じ。
いやまあ業界狭いので研究室以外で5人も使ってれば日本制覇。
会議本体は これ
「競争環境が著しく変化し汎用アクセラレータの代用可能性が現実化し たため、事業性の観点から「省電力アクセラレータ開発」は辞退を判 断しました。」
そうですか、みたいな。まあ確かにアクセラレータの目標が 「現行汎用CPUの性能あたりの電力量を1/10以下」「メモリ転送性能5 TB/s以上の実現」 では、、、この汎用CPUって A64fx でもなくて Xeon か SX だろうし。
そもそもなぜこの目標で始めたんだろう?
{kind=link}
{kind=link}