1スレッドの性能を極端に落とさずに演算器の数を増やすには色々なアプロー
チがありえますが、実際に採用されているのは
-
SIMD 拡張命令
-
ヘテロジニアス・マルチコア
のどちらかです。ヘテロジニアス・マルチコアのことはまた後で触れることに
して、ここでは SIMD 拡張のことを考えてみます。
現在では SIMD 拡張としてもっとも広く知られているのは Intex IA32
(x86-64 となってこの名前もなんだか座りが悪い)の SSE/SSE2/SSE3 でしょう。
これは、基本的には 128 ビット幅のレジスタを 8 (x86-64 では16だだったよ
うな)ワード用意して、それを 32ビット単精度 4 語あるいは 64 ビット倍精
度 2 語の固定長ベクトルとみなし、その各要素に同じ演算をする命令を用意
する、というものです。
ソフトウェアの側から見るなら、 Cray-1 のベクトルレジスタが 64 語だった
ものが 2 語になった、と見ることもできなくはありません。しかし、ハード
ウェアの実装は根本的に違います。ベクトル計算機では長いベクトルレジスタ
に対して演算器は(もっとも単純な形では)1つだったのに対して、SSE/SSE2 で
は基本的には 4/2 個の演算器が並列に動くからです。
この違いは、なんのために SSE 命令なりベクトル命令なりを導入したか、と
いう目的の違いによっています。既に見たように、ベクトル命令は比較的簡単
なハードウェアで1つの演算器を有効に使うために導入された、といってよい
と思いますが、 SSE はありあまるハードウェアを少しは演算にも使おうとい
うものです。
SSE の前身は MMX で、64ビットレジスタを 16 bit の整数4語(8ビット8語も
あったと思います)に分けてそれらに同じ演算を行うというものです。歴史的
には、それを 32ビット浮動小数点 4 語に拡張したのは AMD 3DNow! ですが、
後発の Intel SSE のほうが広く受け入れられたようです。このような形の並
列処理自体は、ゲームコンソール用の CPU、例えば Sony PS2 用のプロセッサ
や 日立 SH4 で使われたほうが先だったと思います。これらのもっとも直接的
な応用は座標変換で、ジオメトリ演算が 4x4 の行列演算になるので、長さ 4
のベクトルを扱ったり、 また内積をとったりする命令をつけているわけです。
演算器の数を増やして並列に実行できる演算数を増やすやり方は理論的には色々
ありえるわけですが、実際に使われているのは基本的には以下の3つです。
-
スーパースカラ
-
VLIW
-
SIMD
それぞれ、どういう考え方かを簡単にまとめると、以下のようになるでしょう。
スーパースカラ: プログラム(コンパイラが出した機械語でも)は1命令が1動作
を記述する。実行時にレジスタアクセス等の依存関係を判断して、どういう順
番で命令を実行するかを決めて、同時に実行できるものは同時に実行します。い
わゆる RISC なプロセッサの場合、 MIPS では R10K, Sparc では Supersparc
以降。 HP は忘れました。すみません。 Power はワークステーション用の系
列では初めからスーパースカラだったような。 Intel は Pentium から。但し、
P5 と P6 以降では本質的に違う実行方式になっています。
VLIW (Very Long Instruction Word) : 命令自体が、同時に実行する複数個の
命令を束ねた非常に長いものになっています。ここから VLIW の名前がでいます。古
典的なものは Multiflow で、7命令とか 14 命令とか 28 命令を同
時に実行できはずです。プログラムは高級言語で普通に書いたものをコンパイラが解
釈して同時に実行できる命令を検出します。というか、少なくとも人間がアセン
ブラを書くのは不可能です。 Multiflow の場合はちょっとしたプログラムでもコ
ンパイルにかかる時間がコーヒー一杯では終わらなかったという話です(今は
IIJ にいる吉村さんから昔聞いたような気がします)。現行の
プロセッサでは Intel Itanic がこれです。
SIMD: 既に述べた通り、1つの命令によって複数の演算器が同じ動作をします。
原理的には、これをさらにスーパースカラや VLIW と組合せることも可能、と
いうか、少なくとも Intel SSE/SSE2 の場合はスーパースカラな実行ユニット
になっていて、ロード/ストアと演算は並列に起こるしレジスタシャドウイン
グもしていると思われます。
これらはどれも、クロックサイクルあたり複数の演算をしようというもの、計
算機屋さんの用語では IPC (Instructions Per Cycle) を上げよう、というも
のですが、ハードウェアの複雑さは並列ユニット数が同じなら
スーパースカラ > VLIW >>> SIMD
という感じになります。スーパースカラは原理的にはもっとも複雑です。問題
は沢山あるのですが、ハードウェアとしては例えばレジスタファイルが非常に
沢山のポートが必要になる、というのが嫌なところです。しかも、シャドウレ
ジスタもいるので語数も増えます。
もっとも、レジスタファイルがややこしいのは VLIW でも原理的には同じです。
28 命令とかいうともう 1 つのレジスタファイルをで読み書きするのは不可能
なので、レジスタファイルををいくつかに分けて命令によってどれに書けるか
が違う、 といった話になります。もちろんその結果コンパイルは一層大変な
わけです。
これに対して SIMD は圧倒的に単純です。レジスタファイルとかでも別にデー
タ幅が広くなるだけでポート数は増えないので、ハードウェア規模が並列ユニッ
トの数に比例してしか増加しません。スーパースカラでは少なくとも2乗程度
でハードウェア規模が大きくなっているようです。
このようなわけで、素人考えでは SIMD が有利なのはあまりに当たり前なこと
に見えます。
しかし、実際のメインストリームのマイクロプロセッサでは、スーパースカラ
が最初に導入され、 VLIW ははなばなしく登場はしたものの主流にはならず、
SIMD の利用は極めて部分的なものに留まっています。その理由はいくつかあ
りますが、大きなものは SIMD はコンパイラ言語からの利用が難しい、という
ことです。
スーパースカラは(実際に上手くいくかどうかは別問題として)、ハードウェア
が自動的に並列処理をするのでコンパイラは普通にシーケンシャルな命令列を
出せばよくて、まあ、上手くいけば高い性能がでます。VLIW も、原理的には
シーケンシャルな命令列から並列実行できるように並べかえるわけですから、
まあ、なんとかなるわけです。どちらの場合でも、基本的にはアセンブルして
から最適化が可能です。
ところが、SIMD 的な並列処理は、並列実行できるループを SIMD 命令に書き
換えるといった、要するにベクトル計算機的な並列化が必要になります。実際、
Intel はベクトル的コンパイラをずっと作っていた KAP (Illiac IV のコンパ
イラをやってたグループが会社になったもの)を買収して並列化技術を導入し
ました(その前には DEC のコンパイラグループも吸収しています)。
さて、では、ベクトル化できるようなプログラムなら SIMD 並列処理で性能がでる
か?というと、実はそうではない、というのが問題の本質です。例えば
do i=1, n
c(i) = a(i) + b(i)
enddo
というのはベクトル化できるループの典型です。もちろん、これから SIMD 命
令を使うアセンブラを出すのは容易なことです。しかし、問題は、このループ
を実行すると演算速度がメモリバンド幅で決まる、ということです。 n が大
きくてデータがキャッシュに入っていないと演算速度は極度に遅くなりますし、
1次キャッシュに入っていても、 2 ロードと 1 ストアで1演算ですから、素
晴らしく気の効いたスーパースカラ実行ユニットがあって、しかも恐ろしくバ
ンド幅の大きな1次キャッシュがあって初めてピークに近い演算性能がでます。
ところが、ベクトル化できるように書かれたプログラムは、原理的にキャッシュ
に収まりにくくなっています。若干抽象的ですが、以下のような計算をするこ
とを考えてみます。
境界条件がどうとか細かいことを別にすると、普通に書いたプログラムの1ス
テップ更新する部分は以下のような感じになるでしょう。
double precision a(n), b(n), c(n)
.....
do i=2, n-1
a(i) = f(a(i),a(i-1),a(i+), b(i), ...)
b(i) = g(a(i),a(i-1),a(i+), b(i), ...)
c(i) = h(a(i),a(i-1),a(i+), b(i), ...)
enddo
f, g, h は実際にはなんか計算式が書かれるわけです。この形のプログラムは
ベクトル化コンパイラが容易に認識してベクトル命令、あるいは SIMD 命令を
使うコードを出すことができます。
あまり意味がある例ではありませんが、 a(i) が単純な拡散項みたいなものだ
と、例えば
do
atmp = a(i)
a(i) = alpha*(atmp+a(i+1)) + (1-alpha*2)*a(i)
enddo
しかし、普通には、この時にベクトル化コンパイラが出すコードは、この各演
算をベクトル命令に置き換えるわけで、原理的には、例えば
x1= a(始点-1ずらした)+a(始点1ずらした)
x2= x1*alpha
x3= (1-alpha*2)*a
x4= x2+x3
a= x4
というような演算を配列全体に適用するわけです。ここで、配列 a のサイズ
がキャッシュより大きいと、これらの各演算でデータを主記憶から持ってきて
主記憶に書き戻すことになって、演算器のピーク性能は全くでなくなります。
もちろん、ベクトル化コンパイラが十分に賢いならばこういう無駄は起きない
わけで、キャッシュに入る範囲に収まるようにループを分割すれば多少はまし
になります。 ベクトル計算機の場合にはベクトルレジスタの長さでループを
分割するのに対応するわけで、これはできないことではありません。但し、現
在のところそういう処理を自動的にするコンパイラはないと思います。
自動的にやったとしても、例えば a, b, c と複数の配列があると、同時にア
クセスする領域がちゃんとキャッシュ上で共存できるような工夫も必要になり
ます。これも理論的に不可能、というわけでではありません。多次元配列にな
るとさらに面倒ですが、まあ、できなくはないでしょう。
これに対して、ベクトル化しない普通のスカラ計算機では、 a, b, c の1要素
がはいった構造体の配列、という形にすることでキャッシュ上でデータがぶつ
かる可能性をほぼ 0 にでき、高い効率を保証できます。n個の演算器が並列に
動作する SIMD 命令に対応するなら、配列のn要素毎に構造体にしたものにす
ればいいし、そういうふうにコードを書き換えることは不可能ではないし、コ
ンパイラがするのも可能でしょう。
しかし、それでいいか、というと実は SIMD 命令の場合はまだ駄目、というの
が問題です。これは、現在のほとんどの SIMD 拡張命令では、2語とか 4 語を
アドレス境界をまたいでロード/ストアすることができないからです。 つまり、
aが16バイト境界から始まっていたとすると、 a(0), a(1)を一つの SIMD 命令
でロードすることは出来ても、 a(1), a(2) をロードすることはできないわけ
です。
これは、ハードウェアの作りやすさを考えると不思議な話ではありません。
128 ビットのデータを読出すのに 128 ビット幅のメモリがあったとすると、
a(0), a(1) を読んで演算器 0, 1 に送るには単にアドレスをいれてデータが
でてくればいいわけでですが、 a(1), a(2) では128ビットのデータの上位64
ビットと下位 64 ビットでは違うアドレスがはいった上に、でてきたデータを
入れ替えないといけないからです。 演算器2つなら入れ替えの回路や別アドレ
スを入れる回路をつけるというのも考えられなくはないですが、演算器が 4
つとか、それ以上に増えると入れ換えのための回路は演算器数の 2 乗に比例
して大きくなり、速度低下にもつながります。
このようなわけで、 SIMD 命令はハードウェアが極めて簡単ですむ、というメ
リットはあるものの、実用的なプログラムで性能がでるようにしようとすると
どんどん複雑になる、ということになります。実際、 SSE3 になってロード/
ストア命令のバリエーションが増えているのはそういうことです。
結局、、 SIMD 命令を使いやすくするにはベクトル計算機並の強力なメモリア
クセス機構をつけないといけない、ということになって、あまりありがたくな
いわけです。 SIMD なら演算器を無制限に増やせそうなのに、そうなってい
ないのはその辺に理由があります。
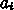 ,
, 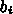 ,
, 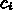 がある
がある