39. ベンチマークの考え方 (2006/12/14)
さて、ベンチマークです。計算機アーキテクチャに対してなんらかの方法で定
量的な評価をしながら作るとすれば、結局それはベンチマークをするというこ
とです。
問題は、ではどうやってベンチマークを選び、どうやって測定するか、という
ことです。どういう方法が正しいか、というのは良くわからないので、まず現
在どういう方法がやられていて、どういう問題があるか、というのを考えてみ
ましょう。
ここ15年ほどの間、複数の計算機アーキテクチャ間の比較に使われる標準的な
ベンチマークというと spec でした。これは、
浮動小数点演算向きベンチマークとして
上のアプリケーションを見ると、いくつかのものは単純な行列演算とか FFTと
いった処理が計算量のほとんどを占めますし、分子動力学のように、粒子間相
互作用の計算が計算量の大半を占めるであろうものもあります。そういったも
のは、本来は計算量が多いルーチンを最適化するとか、あるいはアーキテクチャ
に適したアルゴリズムに変更することで与えられたアーキテクチャで高い性能
を出すことができます。
しかし、SPEC ベンチマークではソースプログラムを与えているので、そうい
う最適化はコンパイラでできることしかできないわけです。それが十分かとい
えば、多くの場合に十分ではありません。このような、ソースプログラムを与
えるベンチマークでは、そのようなわけで何を測っているのかはあまり明確で
はありません。もちろん、実際の使い方がそういうものなのだから、ハードウェ
ア、コンパイラを合わせた総合性能が大事であってチューニングしたら性能が
でる、というようなピーキーなアーキテクチャでは困る、という立場もありえ
ます。
一方で、ハードウェアの色々な高速実行機能をコンパイラが殆どサポートでき
ていないような場合でも、アプリケーションを与えた時のアーキテクチャに人
手で最適化することは、そのアプリケーションの中身とアーキテクチャの中身
が両方良くわかっている人にはそれほど難しいことではないでしょう。実際問
題として、世の中の色々な計算量が多いアプリケーションはそういうふうに最
適化されています。
これに対して、 SPEC はそのようなアーキテクチャ固有の最適化をなるべく排
除するという思想で設計されてきています。その極端な例が SPECfp92 からの
matrix300 で、これは単なる行列乗算のルーチンなのですが、これくらいなら
コンパイラで素晴らしく最適化して浮動小数点演算器の理論ピークに近い性能
がでるようになりました。これが高すぎるというのでベンチマークから外され
てしまいました。
これとは全く逆の思想なのが Top500 で使われている HPC Linpack です。こ
れは、「直接法で密行列の連立1次方程式を解く」ということが指定されてい
るだけで、ソースコード指定どころか、指定は入力の行列の生成方法と
最終結果の精度、あとは「演算量が減るようなアルゴリズムを使ってはいけな
い」というだけで、それ以外は一切なにも規定がありません。従って、並列化
の方法の工夫、演算順序の変更、ループ構造の変更、データ構造の変更といっ
たあらゆることが許されています。
このため、ある程度「まとも」な設計がされている機械ならピーク性能の 7-8
割とかそれ以上はでます。現在のところ、 Top 10 の効率は
この数字は結構厳しいものにもみえますが、
アクセラレータを用いた ヘテロ型スーパーコンピュータ上の 並列計算
という発表資料によると以下のような話のようです。
少し話がそれましたが、そういうわけで現在では HPC Linpack はピークの
80% 前後の数字がでるのが当たり前で、だからベンチマークとして意味がない
といった意見も聞かれるわけです。しかし、ほんの3年ほど前を見ると、
Top 20 の中に効率 50% 前後のシステムが多数あり、またアメリカの ASCI プ
ロジェクトで調達された機械はどれも 60% 前後で決して高くないものでした。
効率が上がったのは、Linpack ソフトウェア自体の効率化もあるかもしれませ
んが、行列乗算ライブラリのチューニング、ネットワーク通信ライブラリのチュー
ニング、ネットワークトポロジの効率化といった努力の成果と思われます。
ネットワークに関しては、例えば現在 Infiniband スイッチの最大手メーカー
である Voltaire 社では、相当な大規模ネットワークでも Clos ネットワーク
をとることを推奨しています。Clos は3段にネットワークスイッチを接続する
ことで大規模ネットワークを構成する方法ですが、中間層のポート数を端より
大きくすることで任意のノードから任意のノードに、決して他のノードの通信
ん邪魔されることなくて通信できる(ノン-ブロッキング)という理想的な性質
をもたせることができます。昔は、ノン-ブロッキング Clos なんてのは理論
的には可能だけどネットワークのコストが高すぎてあんまり現実的ではない、
と思っていたわけですが、多ポートのスイッチが1チップでできるようになり
非常に安価になってきたので結構大規模なものが現実的な値段でできるように
なったのです。
もちろん、並列化やアルゴリズム自体のチューニングも進んで、結局現在では
HPC Linpack は演算に関しては行列乗算さえ速ければ性能がでる、というとこ
ろまできています。このため、行列演算と FFT 以外はチューニングされたラ
イブラリが存在しない Clearspeed でも理論限界に近い速度が実現できるわけ
です。
まあ、そういうわけで、 HPC Linpack で性能を出すなら行列積専用計算機を
作ればいいんだから、そんなのは汎用計算機の性能とは無関係である、という
主張は
行列積専用計算機というのは、文字通り、行列積
例えば、現在の ClearSpeed のように転送幅が 1GB/s の場合を考えてみると、
これは B を送るのと C を回収するのに 500MB/s、つまり 62.5MW/s の速度と
いうことになります。行列のサイズを
逆にいうと、ClearSpeed では行列サイズが 800 もあれば理論ピーク性能がで
てもいいのですが、そうなってはいません。なぜそうなっていないかをアーキ
テクチャの面からもう少し検討してみましょう。
ClearSpeed ボードは CSX 600 チップが2個のっています。1チップには 6KB
のメモリが 96 ブロックあり、全部で 72 K語、つまりチップ 2 つではサイズ
384 の行列を格納できます。もしも、このチップ内のメモリだけを使って行列
乗算をしようとしたら、理論的にはピークの半分しかでないはずということに
なります。
でも、これで計算があっているかというとそんなことはありません。オンボー
ドで 3.2GB/s と高速なメモリをチップ毎につけていますから、チップに載せ
る行列は 128 程度のサイズで十分です。もっとも、オンボードメモリを有効
に使うにはかなり複雑な処理が必要です。
まず、チップレベルでどうやって行列乗算を実現するかを考えてみます。
単純なアルゴリズムでは、例えば CSX600 の PE の 6KB のメモリ一杯に A の
1行をいれます。この時、行の長さは 768 になるわけです。これが 96 本あり
ます。 これと B の 1 列との積を計算することを考えると、単純には B の要
素をクロックサイクル毎に全 PE に放送して、A の要素と乗算、積算すればい
いことになります。ここで、 B の長さを 1500 程度にとっておけば、 C は
1500 サイクル計算したあと 96 要素しかでてこないですから、 PCI-X で2チッ
プ分を回収しても十分間に合うはずです。
これは チップだけの話で、外部メモリにいつデータを送るかを考えていない
のですが、その辺までちゃんと考えると、以下のような手順になります。
ここで、行列サイズが 3072 の正方行列どうしの乗算をすることを考えると、
B を1度送ってから A は4回送って計算することになりますからBの転送にかか
る時間は相対的には 1/4 になり、効率は 83 % 程度まで向上します。ボード
上の2つのチップで同じ B を使うことを考えるとここはさらに半分になるので、
87% 程度の効率は期待できるはずです。さらに、B ひとつを計算している隙間
の時間に次の B を送ることも可能なので、さらに効率を上げることが可能な
はずです。
ところが、実際の効率は 45% 程度なので、上に書いたような調子では計算で
きていなくて、どこかにボトルネックが発生していると思われます。
ここでいいたいことは何かというと、行列積演算というのはそんなに簡単なもの
ではなく、例えば加速ボードのようなものはボトルネックが起きないように注
意深く設計しないとできてからびっくり、といったことが起きるということで
す。
行列積を計算するシステムを設計する時に特に問題になることは、演算チップ
のオンチップで高速アクセスできるメモリ量と演算チップの入出力バンド幅で
実現可能な速度が決まってしまうということです。例えば、 1Tflops のチッ
プに、入出力双方向 2GB/s の転送速度、つまり 250MW/s の速度をもたせたと
すると、データ1つに 4000 演算必要になりますから オンチップで持つ行列サ
イズが 2000 必要になり、 32 MB もの巨大なメモリが必要になります。
もっとも、必要なメモリサイズは入出力速度の2乗に反比例するので、 4GB/s
にすれば 8MB、 8GB/s にすれば 2MB となってだいぶ減ります。しかし、
8GB/s の場合でも、例えば 512 プロセッサとすれば1プロセッサあたり 4KB、
つまり 32Kビットのメモリであり、 メモリ1ビットに 6 トランジスタとすれ
ば 200K トランジスタにもなります。 これは乗算器のサイズ以上です。
そういうわけで、行列積ができるような「専用」チップを作ると、どうしても
演算器に対してメモリが大きいようなものになってしまいます。それなら、後
は演算器とメモリをペアにした単純なプロセッサを沢山並べてしまえばいいわ
けで、 ClearSpeed や GRAPE-DR でやっているように SIMD プロセッサにして
も特に損をするところはありません。
つまり、実際にハードウェアを作る、という観点からは、 Linpack 専用機と
いうのは殆ど意味がないもので、プログラマブルな計算機に比べて有利になり
ません。これは GRAPE の場合とは非常に違います。 GRAPE の場合は、オンチッ
プメモリは必要ありませんし、相互作用計算に完全に専用化したパイプライン
を構成することで、一つ一つの演算器をかなり小さくすることができます。具
体的には、普通の計算機にもたせるには無駄が大き過ぎる $
Linpack 専用機では、倍精度乗算、加減算は必須であり、またメモリも必要な
ので GRAPE のような最適化の余地はほとんどありません。
少し話が散漫になったのでまとめると、ハイエンドの計算機をつくろうという
ときにベンチマークに頼るのは、例えば HPC Linpack のようななんでもあり
のベンチマークにしないと非常に危険で、アーキテクチャの進歩を阻害します。
特にソースプログラムを固定するものはスーパーコンピューターのベンチマー
クに使うべきではありません。
また、 HPC Linpack も行列積の性質上
定量的なベンチマークにもとづいて計算機を設計するべきという理念は美しい
のですが、実際にそれを適用する時にはそれで何をしたいのかという方向を見
失なわないようにする必要があるわけです。
GRAPE-DR の場合には、基本的に これまでの GRAPE でできたことができた上
で行列積も理論ピークに近い性能がでるように、という方針で設計しました。
それでは他のアプリケーションには使えないか?というと、最近色々な人と色々
な検討をしているのですが、意外にそうでもなくて色々なアプリケーションで
結構高い性能がでる、ということがわかってきています。実際に、チップの通
信バンド幅やメモリサイズに対する要求は、行列積はかなり厳しいほうになり
ます。
もっとも、もっとはるかに厳しいものに FFT があり、GRAPE-DR では FFT で
高い性能を出すことは初めから断念しています。
スーパーコンピュータ用のベンチマークとして最近提案されているものに
HPC Challenge というものがあります。
これは以下の 7 種類のベンチマークプログラムから総合的な性能を評価しよ
うというものです
普通はベンチマークは実用アプリケーションではありえないほど高い性能がで
て、だからベンチマークはあてにならない、というものなのですが、 HPC
Challenge では今のところベンチマークのほうが実用アプリケーションよりも
はるかに低い性能になっていて、全く意味がないわけです。
既に書いた通り、スーパーコンピューターの特性は、計算速度、メモリバンド
幅、通信バンド幅でほぼ決まるので、ベンチマークは、
というものです。現在まだ広く使われている specCPU2000 では、整数演算向
きベンチマークとして
168.wupwise QCD
171.swim 浅水波
172.mgrid マルチグリッド。 NAS parallel の MG が元
173.applu 楕円型偏微分方程式。 block SSOR
177.mesa OpenGL 風何か
178.galgel 非圧縮 CFD。スペクトラルガレルキン法
179.art ニューラルネットワーク
183.equake 地震波
187.facerec 画像認識
188.ammp 古典分子動力学
189.lucas 素数判定(FFT)
191.fma3d 有限要素法
200.sixtrack 加速器の中の粒子軌道シミュレーション
301.apsi 気象計算
の 14 個が使われています。CPU2000 の場合はそもそも並列化されてなくてあ
んまり意味がないので、並列化された HPC アプリケーション用の HPC2002 と
かを使うべきという考え方もありますが、これは殆ど誰も使ってないのでここ
では取り上げません。
順位 機械 速度 効率 備考
1 BG/L 280 0.765 IBM Bluegene/L
2 Red Storm 101.4 0.796 Opteron (Cray XT3)
3 BG/L 91.3 0.796 IBM Bluegene/L
4 ASC Purple 75.8 0.817 IBM Power 5
5 MareNostrum 62.6 0.665 PPC 970
6 Thunderbird 53.0 0.85 Xeon 3.6GHz
7 Tera-10 52.8 0.828 Itanium 2
8 Columbia 51.9 0.851 Itanium 2
9 Tsubame 47.4 0.577 Opteron+Clearspeed
10 Jaguar 43.4 0.784 Opteron (Cray XT3)
....
14 ES 35.9 0.875 Earth Simulator
という感じです。効率は大体 80% 前後にきていることがわかります。参考に
地球シミュレータの数字を出しましたが、特異的に高いです。なお、効率最低
は東工大の TSUBAME システムで、60% を切っています。ちなみに、2006年6月
にはこのシステムはピーク 50Tflops Linpack 38.2 Tflops で 76.6% の効率
を出しており、効率がさがったのは ClearSpeed を動かしてピーク性能が 6割
以上つみあがったのに Linpack の数字は 25% しか上がらなかったからです。
要するに、名目 90Gflops のカードで行列積演算では実は35Gflops 程度しか
でないので、どんなに頑張っても 13Tflops 程度しか性能向上はできないわけ
です。その状態で 10Tflops 近い性能向上を実現したのですから、東工大の関
係者は素晴らしい仕事をしたと思います。また、行列積の計算が速くなればそ
れだけ全体の性能を上げることができることが示されたという意味でも大きな
意義があります。
というところになります。もっとも、もうちょっと大事な問題は、では行列積
専用計算機というのはどれくらい専用か、ということです。


という手順で計算すればいいことになります。もっとも、少し考えてみると
というふうにすればよくて B, C はボードに全体を置く必要はないし、また
上の 2-4 は全部並行してできるので、ボードメモリに A, B, C を全部置く必
要はなくて A だけ置ければいいことがわかります。さらに、複数の行列積を
計算するとすれば計算している間に次の A を送ることができればピークに近
い性能がでます。また、ここでの A, B よりも大きな行列積をするとすれば、
A を送ってから長方形の B を送って計算、C を回収、ということができます。
この時には、
という条件下で、行列サイズを大きくしていけばピークに漸近する性能が実現
できます。
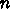 とすると、1語あたりの演算量は
とすると、1語あたりの演算量は
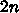 なので、例えば行列サイズが 512 なら速度は 62.5Gflops まで、4096
なら 512Gflops までは転送速度が追いつくことになります。
なので、例えば行列サイズが 512 なら速度は 62.5Gflops まで、4096
なら 512Gflops までは転送速度が追いつくことになります。
この手順で、例えば A B 共に長い辺が 3072 だったとすると、
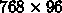 要素をホストから外部メモリに送っ
ておく。この間は計算できない。
要素をホストから外部メモリに送っ
ておく。この間は計算できない。
B のホストからの転送に 38ms
計算は 76ms
A の外部メモリからの転送に 6ms
ホストからの A の転送と C の回収は両方合わせても 計算時間より短い
となり、効率は 63% 程度です。但し、これは実は A, B の長い方の辺のサイ
ズに依存しません。まあ、 PCI-X で1 GB/s がでたと仮定しているので、この
仮定がこけると 50% くらいまで落ちるかもしれません。
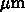 ルールで 400個もの演算器をいれたわけで、
20倍程度のトランジスタを使った GRAPE-DR で 1000 個しか演算器がないのに
比べると 10 倍近く効率が良いわけです。
ルールで 400個もの演算器をいれたわけで、
20倍程度のトランジスタを使った GRAPE-DR で 1000 個しか演算器がないのに
比べると 10 倍近く効率が良いわけです。
に重点を置くものになってしまい、多くのアプリケーションでこれらが本当に
必要かどうかはアルゴリズムを詳細に検討しなければわかりません。
HPL: 要するに HPC Linpack
DGEMM: 純粋な行列積
STREAM: ローカルなメモリバンド幅のテスト
PTRANS: 並列行列転置
RandomAccess: ローカルなメモリランダムアクセスのテスト
FFT: 大規模な FFT
Communication bandwidth and latency: 色々な通信パターンでの性能テスト
これは色々要領を得ないベンチマークで、 HPL があるなら DGEMM を別に測る
ことに意味はなかろうとか、PTRANS と FFT も同じようなものなので意味はな
いとか、これらはどうせ通信バンド幅を測っているだけなので別に通信バンド
幅を測るのは意味不明であるとかいう問題がありますが、
という基本的な性能要件をそのまま測っているもので、意味ははっきりしてい
ます。が、 HPL は HPC Linpack のような無制限なチューニングを許してはい
ないようなのでやはりコンパイラのできや、ソースプログラムとの適合性がみ
えるものになっています。具体的には、 HPL の数字も HPC Linpack の数字に
比べて最適化を許す結果でも 10% 程度低くなっています。また、原因ははっ
きりしていないのですが、 FFT の数字は NEC SX-8 でも HPL の数字の 1/7
程度と極度に低くなっています。 地球シミュレータでは大域 FFT でピークに
近い数字がでていましたので、 HPC Challenge の FFT の数字は最適化したバー
ジョンでも実用コードの数字とはかけ離れたものになっているわけです。他の
多くの機械では HPC Challenge の数字は HPL の 1/50 から 1/100 程度まで
落ちていて、いくらなんでもここまで低いものではありません。
をみれば十分です。考え方としては、これらの基本的な性能から、実際のアプ
リケーションの性能は予測できますから、予測したものと実際のアプリケーショ
ンでの実測値がずれていればそれはどこか、ハードウェアなりソフトウェアな
りにおかしいところがあるわけで、改善の必要があるわけです。
実際のアプリケーションは、ちゃんと基本的な特性のそれぞれが影響するよう
に複数選定する必要があります。
Previous
ToC
Next