今年度の初めくらいから、文部科学省研究振興局情報課でやっている「今後の
ハイパフォーマンス・コンピューティング技術の研究開発の検討」に関係して、
アプリケーションの特性、エクサスケールの計算機に求める仕様の検討、といっ
た作業が始まっていて、AICS の富田さんと私でその取りまとめをする、とい
うことでここ数ヵ月色々な分野の人に協力をお願いして調べています。
そうすると、一つなかなか興味深いことがでてきました。量子化学計算では
多くの場合にそこそこ大きなサイズの密行列の固有値・固有ベクトルを求める、
あるいは対角化するところが計算量の殆どを占めていて、計算アルゴリズムは
ブロック化すると主要な計算は要するに密行列同士の乗算になる、ということ
です。
密行列の乗算はもちろん現在のメモリ階層が深い CPU でもアルゴリズムを工
夫すればほぼ理論ピークに近い性能がでます。 NVIDIA のGPUでは色々制限が
あって Fermi では理論ピークの 70% 程度が限界のようですが、AMD のでは
90% 程度は可能です。GRAPE-DR でももちろん90%以上が達成できます。
但し、これらはいずれもかなり汎用的でプログラム可能な計算機を DGEMM だ
けをするのに使う、というものです。それによってどれくらい損をしているか、
ということを考えるには、 DGEMM だけを最高効率でするような専用プロセッ
サを考えるとどうなるか、をみておく必要があります。また、上に書いたよう
な事情で、重要なアプリケーションの中に DGEMM が実際に計算量の大半を占
めるものがあるので、そういう計算機を作る、というのも現実の可能性でない
わけでもないでしょう。
色々細かいことはありますが、ここではまずチップの外からみてどういう演算
手順かを決めることにします。これは、内部メモリのサイズに対して必要入出
力幅が恐らく理論下限と思われる GRAPE-DR で使っている方法をとります。こ
れは、
という行列乗算をするとして、ブロック化アルゴリズムでは基本的に
A が縦長、Bが横長になります。基本的には、A を正方行列に分割して
それをチップ内部のメモリにロードし、 B を1列(ないしはこのレベルでブロッ
ク化する場合には適当な複数行)ロードしては matrix-vector product を計算
して出力する、というのを上手くパイプライン化して B のロード、演算、
Cの出力が並行して進むようにします。
この場合、チップ内にメモリが 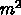 語あると、
語あると、  語入力・出力する毎に
乗算、加算がそれぞれ
語入力・出力する毎に
乗算、加算がそれぞれ 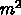 回で、入出力合わせると 1 語当り
回で、入出力合わせると 1 語当り  演
算となります。
演
算となります。
GRAPE-DR では、プロセッサの数が 512 で自然数の2乗になってないために少
しややこしいので、以下 1024 プロセッサとして話をします。
この場合、GRAPE-DR の方式では、各プロセッサが 256 語のメモリを持ち、
それぞれ 16x16 の小行列、全体で 512x512 のA行列を持ちます。
長さ 512 の b ベクトルを32 に分割して、32x32の列毎に同じデータを放送
し、 サイズ16の行列・ベクトル乗算のあと行方向に合計すると c のベクトル
ができます。GRAPE-DR の場合には、放送・合計にそれぞれ専用ネットワーク
を使っていて、プロセッサの物理配置は同じ列にあたるものをブロックにまと
め、列に対応するものをさらに2次元配置しています。
このやり方には、ちょっと見たところ以下のような問題があります。
-
1本の b との乗算で A の全部をなめるのでオンチップでプロセッサローカ
ルで良いメモリとはいえ B/F=4 が必要である
-
レジスタはその割に沢山いる。演算器1つにつきbを格納するだけで16語は
いる。レジスタもサイクル毎に1語読み出しと、あと積算レジスタが必要で
ある。通信バッファ的なものも何かしら必要であろう。
Aの行列をしまうメモリの必要バンド幅を減らしておくと、動作速度・消費電力
的には有利になります。このための1つの方法は、メモリを複数の演算器で共有
し、メモリからのデータを放送することです。例えば4個の演算器で b 4本を並
列処理することにすれば、これらはメモリを共有してよいことになります。但
し、単純にやるとこの場合演算器当りで必要なレジスタ数は倍に増えてしまい
ます。
bのほうは列方向には放送されるわけで、読み出しレジスタは複数プロセッサ
で共有することも可能です。また、アキュムレータは4語程度もたして時分割
動作させることで論理的なプロセッサの数を増やせば、 b のバンド幅を減ら
すこともできます。
このようにみていくと、
-
ブロック化のためにはある程度のオンチップメモリは絶対必要
-
GRAPE-DR の方式では、オンチップメモリ、レジスタから
演算器・マシンサイクル毎に1語読み出し、アキュムレータに積算する
必要があり消費電力的には若干まだ改善の余地がある
-
原理的には、GRAPE-DR の方式に比べて演算器・アキュムレータ以外の
部分の消費電力を数分の一にすることは可能
となります。トランジスタ効率でも倍程度は良くできる可能性があります。但し、
GRAPE-DR の場合には1プロセッサに入る範囲では任意の計算ができたのですが、
メモリアクセスやレジスタアクセスにも制限がある、ということになるので本
当にこんな代物を作るのがよいことがどうかは問題です。少なくとも、他の色々
なアプリケーションで意味がある性能になるかどうかは考えておく必要があり
ます。
オンチップメモリを複数プロセッサで共有にするのは、重力相互作用のような
タイプの計算では中間変数がレジスタに収まるならば問題ありませんが、例え
ば量子化学計算での2電子積分ではどうかというと、まあ多分大丈夫ですが精密
な評価は必要です。
チップ上のネットワークについては、GRAPE-DR の方式の特徴は階層的であって
2次元メッシュではない、ということです。つまり、チップ上でのバイセクショ
ンバンド幅は極めて小さく、配線に使われている資源も小さく、大域的な長い
配線もないしメッシュ結合のように冗長性がない短い配線が大量にでるわけで
もありません。このため、ネットワーク、プロセッサ、プロセッサブロックの
どのレベルでも冗長性をもたせることが原理的には可能であり、不良率の少な
いプロセッサを作ることができます。
なお、ここまでの考察ではメモリリソースを全てローカルメモリにして必要な
入出力バンド幅を最小化していますが、それで現実的な通信速度になっている
かどうかは注意が必要です。
例えば 28nm プロセスで 90nm の GRAPE-DR と同様なチップサイズで作ると、
1GHz 動作 4096PE としてチップ性能は 8TF となります。これは GRAPE-DR 1
ボードの大体10倍ですので、通信が実効で10倍の 16 GB/s でてもメモリはサイ
ズ 2048 の正方行列、つまり 32MB が必要です。これはGRAPE-DR のローカルメ
モリがトータルで1MB であったのに比べて、シュリンクを考慮してもさらに3倍
ほど増えている計算になり、高密度・低速の SRAM や embedded DRAM を使う必
要があると思われます。もっとも、GRAPE-DR ではローカルメモリのチップ全体
に対する面積の割合は1/8 程度であり、3倍に増えてもいけないわけはありませ
ん。ホスト計算機との性能バランスは、従来の3年で4倍のペースが今後も続く
なら2-3年後には 10-20倍 程度になって、LINPACK には具合がよいくらいだと
思われます。
以下が Intel Xeon のここ十数年の性能です。
2012 Sandy Bridge 8core 8 ops 3GHz = 200Gflops
2009 Nehalem 4 4 3 50
2006 Clovertown 4 4 3 50
2001 Foster 1 2 1.6 3.2
1999 PenIII 1 1 0.7 0.7
割合綺麗に 3 年で4倍を続けていることがわかります。Clovertown であげた
あと Nehalem で一回休みしてメモリバンド幅強化していますが、これはここ
でやっと AMD 並のメモリ直結アーキテクチャにできたのでしょうがないとこ
ろでしょう。
まあ、実用アプリケーションで DGEMM や相互作用計算するものでは、LINPACK
でバランスがとれる程度では加速率が低過ぎることが多く、バランスとしても
う数倍速いもののほうが本当は良いのです。が、汎用というか DGEMM できるよ
うに作ると LINPACK で性能がでないと設計失敗みたいに言われるのがつらいと
ころではあります。数年たってホストの性能が上がれば問題は解消するわけで
すが。これは、逆にいうと GRAPE-DR でもそうであったように、DGEMM で性能
がでるように作ったアクセラレータは一度作れば実効性能や電力性能で汎用プ
ロセッサや他のものを上回る期間はかなり長いということです。
DGEMM だけの専用計算機、というのは私自身のサイエンスへの興味からはあま
り魅力ある計算機ではないのですが、それが重要なアプリケーションである人
は(作るのがそれほど難しいわけでもないので)検討するべきものと思います。
カスタムLSIではない、eASIC のような構造化ASICでは、半導体世代で大体
2.5 世代程度、FPGAでは 3.5ないしは4世代の遅れに相当する性能低下がある
ので、DGEMM に向いた計算機をこれらの技術で作るのはあまり現実的ではなく、
CPU や GPGPU になかなか勝つことができません。
これらの技術での計算機は、演算精度を切り詰め、さらに演算器複数でのパイ
プライン化によってレジスタ・メモリを減らしつつ実行効率も上げる、と
いうことによって初めて汎用プロセッサに対して優位になる、というのは
なかなか変わりません。
