某プログラム、というか、単に独立時間刻みで 1000粒子くらいの
N体系を積分するものを、Xeon 2 ソケットとかのノード内並列で
なるべく速くしたい(ノード間でもいいのですがどうせ速くならないだろうみ
たいな)ということが研究上あって、少し OpenMP をいじっていたのですが、
OpenMP の同期等のオーバーヘッドが巨大で、普通に書いたのではなかなか
速くならない、ということがわかってきました。
独立時間刻みのプログラムは以下のような構造をしています。
-
次の時刻と、そこで積分する粒子群を決める(アクティブ粒子)
-
全粒子のその時刻での位置を予測する
-
全粒子からアクティブ粒子への力を計算する
-
計算した力を使って、アクティブ粒子をアップデートする
-
1 へ戻る
計算量のほとんどはステップ2,3なので、ここは並列化も SIMD 化もちゃんとす
る必要があります。細かいことをいうと、2は少ないのでSIMD化か並列化のど
ちらかができていれば十分です。
1は少ないので、並列化しなくてもなんとかなります。4 は
少ないのですが、粒子数が少ない時には馬鹿にならないので、並列化はできて
いることが必要です。
OpenMP で普通に並列化すると、2,3,4 に対して対応するループがあるので、
それに対して pragma をつけることになるわけですが、これでは
最低3回、どうかするとさらに大きな回数の並列ループが積分の1サイクル毎に
起動されることになってかなり大きなオーバーヘッドが発生します。
並列ループ起動のオーバーヘッドをなるべく小さくするためには、以下のよう
な構造にすればよいことはわかります。
-
以下の全体を並列実行する
-
全コア同期する
-
次の時刻と、そこで積分する粒子群のうち自分が担当する粒子を決める
-
全粒子のその時刻での位置を予測する
-
全粒子からアクティブ粒子への力を計算する
-
計算した力を使って、アクティブ粒子をアップデートする
-
2 へ戻る
但し、OpenMP でこんなことができるプログラムを書くには、かなり大幅な書
換えが必要です。3-6 のステップで使う中間変数はすべてスレッドプライベー
トにとり直す必要があるし、また、全体データへのアクセスでは他のスレッド
とのキャッシュ衝突が避けられないからです。キャッシュ衝突を避けるために
は、粒子データ全体自体をスレッドプライベートに持つ必要がでてきます。
これはなんだか馬鹿みたいな話で、OpenMP で書く利点が完全に失われていま
す。そんなことなら MPI で書くほうがましです。MPI では以下のようになり
ます。
-
次の時刻と、そこで積分する粒子群のうち自分が担当する粒子を決める
-
全粒子のその時刻での位置を予測する
-
全粒子からアクティブ粒子への力を計算する
-
計算した力を使って、アクティブ粒子をアップデートする
-
アップデートした粒子を交換する。
-
1 へ戻る
これはいわゆる i並列というもので、プロセス間で、力を受ける粒子が違うも
のになります。このコードでは、通信と同期がステップ5で行われるわけで、
これは Allgather を1度コールすればよいことがわかります。(vでもいいです
が、アクティブ粒子の数の差は最大1にできるのでallgather のほうが多分よい)
なお、j並列(力を及ぼす側を分ける)も可能で、この場合以下のようになりま
す。
-
次の時刻と、そこで積分する粒子群を決める
-
自分が担当する j 粒子のその時刻での位置を予測する
-
自分が担当する j 粒子からアクティブ粒子への力を計算する
-
アクティブ粒子への力を合計・放送する(allreduce)
-
求まった力を使って、アクティブ粒子をアップデートする
-
1 へ戻る
これはどちらがよいかというと、アクティブ粒子の数が非常に少ない時には、
j並列のほうが有利になる可能性があります。ステップ 2, 3 が短くなるから
です。一方、allreduce は allgather に比べて遅いはずですし、ステップ5が
並列化できない(冗長になる)ことも不利に働きます。
というわけで、ではそもそも1ノード内で
allreduce や allgather の性能はどんなものだろう、ということで測定して
みた結果を以下で紹介します。
CPU は Intel Xeon CPU E5-2650 v22.60GHz (IBコア)で、8コアx2ソケットで
す。MPI は、openmpi-1.6.5, mvapich2-1.9 を使ってみています。gcc は
4.4.7 です。
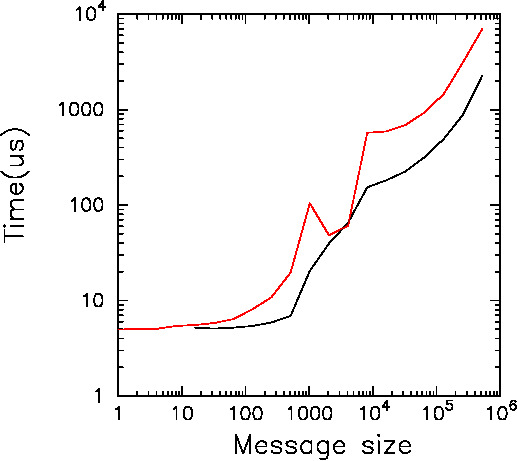
Figure 3: OpenMPI での allgather, allreduce の速度。横軸は
倍精度浮動小数点ワード数(allgather の場合は、送信ワード数にプロセス数をかけたもの)、
縦軸は経過時間(マイクロ秒)。赤が reduce, 黒が gather。
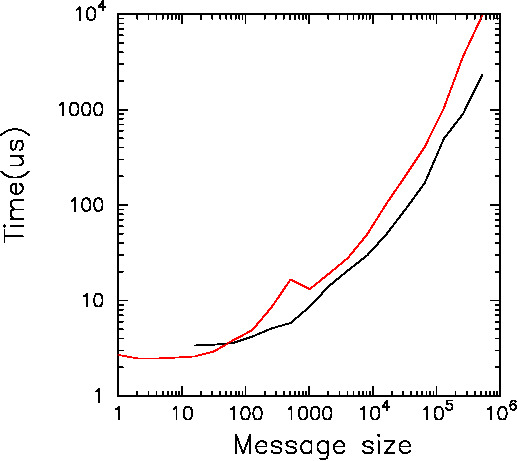
Figure 4: MVAPICH2 での allgather, allreduce の速度。横軸は
倍精度浮動小数点ワード数(allgather の場合は、送信ワード数にプロセス数をかけたもの)、
縦軸は経過時間(マイクロ秒)。赤が reduce, 黒が gather。
この実測値から適当に性能モデルを作って、粒子数 2048 の時の性能予測をす
ると、16コアではアクティブ粒子の数が十分多い時でやっと8倍強(i並列の場
合)で、アクティブ粒子が100以下だとj並列が速い、というような感じです。
アクティブ粒子数が大きいところでは、性能劣化の要因になっているのは
allgather のスループットで、レイテンシではありません。
allgather のスループットは、メインメモリや LLC のバンド幅がみえている
感じの数字で、OpenMP での並列化でもこれより速くはならないと思われます。
レイテンシリミットではないので、原理的には似鳥君の Ninja アルゴリズム
で、 i, j 方向の同時並列化を行うことで1コアの通信量を減らすと
もうちょっと性能が上がる可能性はある、ということになります。
但し、コア間ネットワークがリングや共有メモリというボトルネックを
持つものなので、2次元アルゴリズムにしても原理的にはあまり改善されません。
結局のところ、16コア程度の共有メモリアーキテクチャというのは、コア間通
信バンド幅が実効的に低く、レイテンシも大きいために容易には性能がでない、
というのが、比較的性能をだしやすいN体問題でも実用コードで粒子数が少ない
とやはり見えます。共有メモリ自体が性能ボトルネックを作ってしまうわけです。