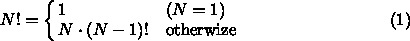2. C++言語入門 II
本章では、後の話で必要になる最低限の C++ の知識ということで、配列と再帰 処理について簡単にまとめる。
本来、 C++ らしい(C や Fortran ではできないような)プログラムスタイル の根幹をなすのは、「クラス」と「テンプレート」であるが、 また後で触れることにしたい。
Fortran でも C/C++ でも、数値計算をする上で基本になるデータ構造は多く
の場合に配列である。
これはもちろん Fortran で
宣言はFortran では
なお、他にも細かく違うところはある。実用上で大事なのは、メモリ上にデー
タがしまわれる順番である。 1 次元配列ではもちろん配列要素が順にメモリ
上におかれるが、2次元配列では 2 つの可能性がある。つまり、最初の要素
data(1,1) あるいは data[0][0] の次に来るのがなにか?であ
る。 Fortran では data(2,1) が来るが、C/C++ではdata[0][1]
が来る。この違いは、いろいろな場面で意識する必要がある。
なお、このC の言語仕様で定義された普通の配列に関する限り、 C/C++ の多
次元配列には Fortran のそれに比べた大きな欠点がある。
それは、関数の引数として配列を渡す時に、大きさを変数として渡すことがで
きないということである。つまり、 Fortran では
もっとも、これはあくまでも汎用のライブラリを準備し、しかもそれをソース
プログラムとしてではなくあらかじめコンパイルしたいわゆるバイナリライブ
ラリとして準備する時にだけ問題になることではある。従って、自分でプログ
ラムを書く場合にはあまり問題にはならない。
コンパイルしたライブラリを作るにはいろいろな方法がある。 C++ では、ユー
ザーが新しいデータ型を定義することができるので、自分で定義してしまえば
Fortran の配列よりももっと便利に使えるものができる。また、既に人が作っ
た便利なものがいろいろあるので、高度なことをするにはそういったものの利
用を考えるベきである。
配列を使う例だが、
計算天文学とはいえ、数値計算ばかりでも芸がないので、ここではちょっと違
うこともやってみよう。
コンパイルして作るプログラムの名前には sort は使わな
いこと。これは、この名前の別のプログラムがあらかじめ準備されていて、そ
ちらが実行されてしまうからである。もちろん、 ./sort と指定すれば
自分で作ったものが実行されるが、いずれにしても混乱する可能性がある。
配列に関しては C++ は Fortran に比べて必ずしも良くなっているとはいい難
い、というか正直いって退化しているが、プログラムの構造という観点からは
いくつか Fortran にはない有用な特色を持つ。その一つがここで述べる再帰
である。なお、最近の多くの Fortran コンパイラでは、言語仕様では再帰を
サポートしていなくても実際には仕様が拡張されていて再帰が使える。また、
F90 は言語仕様として再帰をサポートする。
再帰とは、手続きが「自分自身を呼び出す」ことである。これは、プログラミ
ングの理論的な扱いという観点からも、また、実用上からも非常に重要な考え
方である。簡単な例から考えてみよう。
2.1. 配列
1:// calculate_sum
2:#include <iostream>
3:using namespace std;
4:
5:int main()
6:{
7: int n ;
8: int data[100];
9: int i,sum;
10: cout << "How many numbers you want to input?";
11: cin >> n;
12: for (i=0;i<n;i++) cin >>data[i];
13: sum = 0;
14: for (i=0;i<n;i++){
15: sum += data[i];
16: cout << "data[" << i <<"]=" << data[i] << " sum=" << sum << endl;
17: }
18:}
これは配列を使う簡単な例である。
int data[100] ;
と変数宣言で書くと、100個の整数型変数ができ、それぞれが
data[0] から data[99] までといった風に、番号で指定して操作
できる。
integer data(100)
と書くのとほとんど変わらないが、どうでもいいような違いがいくつかある。
括弧はまあなんでもいいが、添字が 0 からになるのは C/C++ の他の多くの言
語とは違った特異な点である。なお、 Fortran の場合は、例えば
integer data(0:100)
といった具合に「最初と最後」を指定できるので、実は 1 から始めないとい
けないというわけではない。しかし、 C/C++ の場合には必ず 0 から始まり、
それを変更する方法はない。
2.2. 多次元配列
integer data(100,100)
とか書いたが、C/C++ では
int data[100][100];
と書く。使い方も同様に Fortran では data(i,j) のところを data[i][j] と書く。次元が増えても同様である。 Fortran では配列の次元
は 7 次元までとかいう制限があるが、 C/C++ では特に制限はない。
subroutine sub1(a, n, nn)
integer n, nn
real*8 a(nn,nn)
.....
といった形で、次元ごとの大きさを引数として渡すことができる。このために、
汎用の行列計算や連立一次方程式の解法などのサブルーチンを準備するのが容
易である。ところが、 C/C++ では引数としては渡せないので話が面倒になる。
もっとも、Cの最新の言語仕様ではこれが可能になっているが、現在のところ存在
するほとんどのプログラムはこの機能を使わないで書かれている。
2.3. ソート
1:// sort.C
2:
3:#include <iostream>
4:using namespace std;
5:
6:int main()
7:{
8: int n;
9: double data[100];
10: int i,j;
11: cin >> n;
12: for (i=0;i<n;i++)cin >> data[i];
13: cout << "Input data\n";
14: for (i=0;i<n;i++) cout << data[i]<<endl;
15: for (i=0;i<n-1;i++){
16: for (j=i+1;j<n;j++){
17: if (data[i] > data[j]){
18: double work;
19: work = data[i];
20: data[i] = data[j];
21: data[j]= work;
22: }
23: }
24: }
25: cout << "Sorted data\n";
26: for (i=0;i<n;i++) cout << data[i] << endl;
27: return 0;
28:}
このプログラムは、入力した数を小さい順に並べ変えて出力する。並べ変える
原理は、以下のようなものである。
このプログラムを実行するには、まずデータファイルを別にエディタで作って
おく。これは先頭にデータ数を書き、後は一行に一つ数字を書いておけばいい。このデータファイルの名前
を sample.dat、コンパイルしてできた実行ファイルの名前を
simple\_sort とすれば、
./simple_sort < sample.dat
とシェルウインドウで入力すれば結果が得られるはずである。
2.3.1. 注意
2.4. 練習
なお、あるプログラムの実行時間を計るには time コマンドが使える。
time ./simple_sort < sample.dat
という風に入力すると、実行結果のあとにもう一行
0.040u 0.080s 0:00.56 21.4% 0+135k 2+0io 21pf+0w
というような出力が出てくる。この最初の数字が秒単位の実行時間である。な
お、実際にかかった時間はもっと長いことがあり得る。これは、ファイルの読
み書きの時間は正確には入らないこと、また何人かで1台の計算機を使ってい
るとその分余計に時間がかかることによる。
2.5. 再帰