さて、 eASIC です。色々見積もると、 Nextreme-2 で低精度の GRAPE ならチッ
プ当り数 Tflops は容易です。 GPU に比べたメリットは、
というところです。但し、低精度、ということで当然 treecode 用になるので、
性能が通信リミットになるかどうかが問題です。例えば 10TF というのは
300G interactions/sec, 300MHz のクロックで 1000本のパイプライン、という
話でそれほど無理ではありません。
NX21000 で 100万 eCell ですが、まあボード1つに 2-4 チップだと上の数字
くらいになると思われます。
相互作用数を 1000 とすれば、これは 300M 粒子/秒、つまり、3億粒子が1秒
で計算できてしまいます。
こうなると通信が大問題で、結果の加速度をなんとかして4バイトに収めても
12 バイトで、それだけで 3.6 GB/s と普通では不可能な速度が必要です。ま
た、粒子を送るほうはその数倍必要で、 20GB/s とかそういった全く不可能な
速度が必要になってしまいます。現実問題としては高い FPGA を使って Gen2
8 レーン、実力 2GB/s 双方向、といった辺りがボード1枚での限界です。
そうすると、色々邪道なことを考えないといけません。まず、粒子やツリーの
座標データについては、相互作用の精度自体が低いものでよい時にどうやって
送るのが最適か、というのが問題です。例えば、ツリーの大きなセルについて
は、どうせ遠くからしかみないんだから位置が高い精度で決まっている必要は
ありません。
例えば、相互作用リストをモートンオーダーで作ったら、それに対応するツリー
構造が存在していますから、そのツリーのセルの中での相対座標だけを指定す
れば例えば力の精度に 10ビットとるとして、セル中座標にそれくらいあれば
十分なはずです。 モートンキー自体については前の粒子との差をとって、こ
れはしょうがないので可変長にします。原理的に、ほとんどの場合に下のほう
だけが変わるので 1-2バイトでよいはずです。そうすると、結局 40ビット程
度で1粒子が表現でき、普通の場合の 1/3 程度ですみます。
が、この3倍は大きいとはいえ、それでも極限的な転送速度が必要なことに変
わりはありません。
ハードウェアの極限性能も重要ですが、競争相手がどれくらい、というのも考
えておく必要があるでしょう。現在、 CPU を使った並列化された treecode
(TreePM も含めて)でおそらく地球上最高速なのは石山君の GreeM で、
Barcelona 2.2GHz 1コアで 5-70000 粒子/(秒・コア)、つまりソケット当りで
は 20-30万(これおよび以下では単位は秒・ソケットあたりの粒子数)となりま
す。GRAPE 等の時の基本として、「構想段階で 100倍の性能向上」というのが
あるのですが、そのためには 20M粒子でよいことになります。
もっとも、価格の問題はあり、ボードの量産コストが 20万だとすると PC 1ソ
ケットの2倍するので、さらに速度が3倍くらいは本当は欲しい、となって
100M粒子です。そうすると、上の見積もりの20GB/s から圧縮して 1/3、速度
が 1/3 でよいことにすることでさらに 1/3 となり、2GB/s 実力ででるなら
まあなんとか、となります。
GPU と比べるとどうか?というのが一つの問題ですが、例えば Hamada et
al. (2009) によると Core 2 Quad 6600+nVIdia GF8800GTS では、ノード当り
(ノードは1ソケット1カード)35万粒子、となっています。これは TreePM では
なくて pure tree なので計算量は多いですが、それにしても、まあ、これに
比べるなら新しくハードウェアを作った時に 100倍 にするのは決して不可能
でもなさそうです。もっとも、問題になりそうなのは treecode の場合ホスト
でのツリーの構築や treewalk です。ツリー構築(通信も合わせて)は GreeM
では全体の10% 以下なので、数年たってホストが速くなっていることを期待す
ればまあなんとか、となります。 treewalk は遅いですが、これは逆に ng を
大きくするしかありません。つまり、おそらくは 10Tflops/card くらいで、
2GB/s も通信速度があれば十分に演算速度を有効に使える、ということになり
そうです。これはまあそれほど不思議な話でもなくて、 GRAPE-6 の PCI イン
ターフェースに比べると 100倍近く、 GRAPE-7 の PCI-X に比べても10倍近く
加速しよう、という話なので、 10倍程度性能を積み上げても全く問題はあり
ません。
GPU の場合は現在のところ名目ピーク 700Gflops のボードで 160Gflops 程度
で、ハードウェアの計算速度限界に達しているようには見えないです。とすれ
ば、通信リミットなはずです。相互作用リストが 12000, ng が 500 (? 250?)
とすれば、i 粒子1つについて 24 -50 個 j 粒子を送っています。これを16バ
イトとすれば 400-800バイトです。 GPU でPCIe の理論性能の 8GB/s が出れば
10M粒子の性能のはずです。なので、GPU は通信については 30倍くらい謎な部
分があることになります。
GPU が今後数年のうちに謎な部分が直るとも思えないので、結局ツリーコード
での GPU の性能は CPU の1-3倍に留まると思ってよいでしょう。新 GRAPE で
は、現在のCPU, GPU のほぼ100倍の性能を数年後に実現することで、従来の
GRAPE と同様な「圧倒的なメリット」を目指せそうです。
サイエンス、という観点からは、低精度でよいのか?という問題はあるわけで
すが、これについては最近藤井さんや押野君が開発してきたハイブリッドスキー
ム、つまり、遠距離相互作用については tree を使うけれど近距離力には
direct scheme を使う、という方法で基本的には対応できるはずです。これら
のスキームではツリーの部分ではシンプレクティックにすることで、長時間積
分についても十分な精度を維持すると同時に近距離相互作用には高い精度を実
現します。
このスキームを使うためには、近距離側での重力相互作用に適当な形のカット
オフをいれる必要があり、また TreePM と一緒に使うためには遠距離側にもカッ
トオフが必要です。さらにもうひとつ考えるべきことは、多重極モーメントも
いれるかどうかです。例えば4重極は書き下すと以下のようなものです。
r5inv = r2inv*r2inv*rinv
phiq = (-.5*((dx*dx-dz*dz)*
& quad(p,1)+(dy*dy-dz*dz)*
& quad(p,4))-(dx*dy*quad(p,2)+
& dx*dz*quad(p,3)+dy*dz*
& quad(p,5)))*r5inv
phi(pbody) = phi(pbody)+phiq
phiq = 5.*phiq*r2inv
acc(pbody,1) = acc(pbody,1)+dx*phiq+(dx*
& quad(p,1)+dy*quad(p,2)+dz*
& quad(p,3))*r5inv
acc(pbody,2) = acc(pbody,2)+dy*phiq+(dy*
& quad(p,4)+dx*quad(p,2)+dz*
& quad(p,5))*r5inv
acc(pbody,3) = acc(pbody,3)+dz*phiq+(dz*
& (-quad(p,1)-quad(p,4))+dx*quad(p,3)
& +dy*quad(p,5))*r5inv
これは基本的に固定小数点で行うことができるはずです。乗算の精度は3-4 ビッ
ト、加算はもうちょっと必要ですが 6 ビット程度でしょう。そうすると、乗算
31個、加算 18個です。乗算器、加算器ともに 100ゲート程度ですから、全体で
5000ゲートになって、演算器のゲート効率は素晴らしく高いものになります。
単精度の乗算器が 6000ゲート程度ですから、普通なら乗算器1 つしか入らない
回路規模で 50演算くらいできるわけです。これはもちろん、消費電力削減にも
それだけ貢献することになります。
上式は純粋な 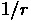 ポテンシャルの場合で、カットオフが入るともうちょっ
と式が複雑になりますが、データ量はあまり変わらないので計算速度と通信速
度の関係からはさらに有利になるわけです。
ポテンシャルの場合で、カットオフが入るともうちょっ
と式が複雑になりますが、データ量はあまり変わらないので計算速度と通信速
度の関係からはさらに有利になるわけです。
GRAPE のような完全に専用化した回路のメリットは、このように極限的にデー
タ長をつめることで普通のプログラマブルな計算機に比べて 1-2桁回路規模を
小さくできることにあります。プログラマブルな GRAPE-DR の場合はこのよう
なメリットは失われており、ASIC ゲート数に対する演算器の数は低精度
GRAPE に比べると 2桁以上低いものになります。もっとも、普通の計算機では
これは3-4桁低いので、 GRAPE-DR にメリットがないわけではないのですが、
GRAPE のメリットは他のやり方が無意味に思えるほど大きいものです。
もちろん、 eASIC のような構造化 ASIC を使うと、回路規模での3桁の差のあ
る程度は失われます。 eASIC の 45nm プロセスの製品は、順調に開発・検証が
進んだとして 2000万ゲート規模、すなわち ASIC ならば1億トランジスタ程度
と 130nm で実現可能であったものがせいいっぱいですから、3世代、つまり大
体 10倍の回路規模の違いがあります。速度については、差は 10倍もなくなっ
ており、開発期間があまり長くなければチップ当りの性能で 1-2桁程度の優位、
消費電力では2-3桁の優位を実現できるわけです。
この、速度差があまり大きくない、というのは、昔からいわれていたゲート遅
延より配線遅延が大きくなる、という要因と、カスタム ASIC やマイクロプロ
セッサの動作速度は既に電力リミットになって久しい、という要因の両方によっ
ています。