Very roughly speaking, the last 10 years of the high-performance computer can be summarized as the slow decline of the vector processors and comparably slow rise of distributed memory parallel processing. This trend is driven mostly by the constraint in the silicon technology [MT98].
As Hillis [Hil85] stressed, there used to be two very different ways to construct a fast computer. One is to connect the fastest possible processors (vector-parallel approach). Since first processors tend to be expensive, the number of processors you can buy used to be small. The other is to connect many relatively slow processors (MPPs). Cray and Japanese manufacturers had been pursuing the first approach, while a number of companies tried the second, with limited success.
In late 1980s, however, two ways started to converge (or, to
collide). The reason is that the microprocessors, which were the
building blocks of MPPs, caught up with the vector processors in the
processing speed. In 1970s, there were the difference of nearly two
orders of magnitude between the clock speed of vector processors and that
of CMOS microprocessors. In addition, microprocessors typically
required tens or even hundreds of cycles for a floating-point
operation. Thus, the speed difference was at least a factor of 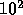 .
This factor could be as large as
.
This factor could be as large as 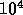 .
.
Today, the difference in the speed has almost vanished. The clock speed of today's microprocessors is considerably faster than that of vector-parallel processors, and microprocessors can perform one or more floating point operations per cycle. Thus, programs that are not very well vectorized or parallelized are actually faster on microprocessors.
As far as the performance characteristics are concerned, today's high-performance computers are not much different from a pile of personal computers connected by a fast network. We need very high degree of parallelism to make effective use of these machines. In addition, practically all machines has non-uniform-access memory architecture (NUMA), which means that we need to design the program so that data are distributed over processors in an appropriate manner. This is true for both the vector-parallel machines such as NEC SX-4 and MPPs like Hitachi SR-2201 or SGI-Cray T3E.
This characteristic of modern high-performance computers has rather strong negative impact on the future of the computational astrophysics. Firstly, to use parallel computer is not easy, even in the case of ideal parallel machine with physically shared memory. Secondly, NUMA machines are far more difficult to program compared to machines with physically shared memory. Thirdly, to develop message-passing style program is even more difficult.
In the case of N-body simulations, just to run a simple,
direct-summation scheme with constant stepsize on a massively parallel
computer is already a difficult task[FWM94]. Implementing a
particle-mesh or P M scheme or treecode with shared timestep is not
impossible, but proven to be a task which can easily eat up several
years of time of a very good researcher, which could otherwise be used
for doing science (see, e.g., [WS92] or
[Dub96] for examples of parallel tree codes). Implementing
an individual timestep algorithm has been demonstrated to be difficult
[Spu96].
M scheme or treecode with shared timestep is not
impossible, but proven to be a task which can easily eat up several
years of time of a very good researcher, which could otherwise be used
for doing science (see, e.g., [WS92] or
[Dub96] for examples of parallel tree codes). Implementing
an individual timestep algorithm has been demonstrated to be difficult
[Spu96].
The essential reason for this difficulty is that parallel computers are designed without any consideration for astrophysical applications, not to say N-body simulations.
In the following, we describe an alternative. Instead of adopting the algorithm to available computer, we design the most cost-effective combination of the algorithm and computer.