In this paper, we briefly overviewed the computational issues of direct N-body simulations and the use of special-purpose computers, and we reviewed the plan and development status of GRAPE-6. We believe GRAPE-6 will give us many new important scientific results, much in the same way as GRAPE-4 have done so in the five years since its completion.
Since GRAPE-6 is now close to its completion, it might be worthwhile
to speculate on what will come next. The silicon device technology has
been advancing as usual, and will do so at least for one more decade
or two. If we will start the development of the new system just after
the completion of GRAPE-6, we will use the technology safely available
by 2002, which is either 0.13 or 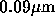 technology. This
will give us around a factor of six increase in the transistor
count. For the clock speed, we expect that the improvement by a factor of
three will not be too hard, mainly because the current clock of GRAPE-6
chip is not very high. Thus, we can achieve about a
factor of 20 improvement in the speed over that of GRAPE-6 chip, reaching around 0.7 Tflops per
chip. With three thousand chips, the peak speed would reach two
Petaflops.
technology. This
will give us around a factor of six increase in the transistor
count. For the clock speed, we expect that the improvement by a factor of
three will not be too hard, mainly because the current clock of GRAPE-6
chip is not very high. Thus, we can achieve about a
factor of 20 improvement in the speed over that of GRAPE-6 chip, reaching around 0.7 Tflops per
chip. With three thousand chips, the peak speed would reach two
Petaflops.
The target number of particles for such system would be around 1 million, for star cluster simulations. For that number, however, one might ask whether or not the direct force calculation is really a good approach, even though it guarantees very good cost-performance ratio.
There are two widely used algorithms to reduce the
calculation cost. One is the neighbor scheme (Ahmad and Cohen
[1973]), and the other is the treecode (Barnes and Hut
[1986]). For general-purpose computers, both algorithms
give pretty large improvement in the overall calculation speed. The
theoretical gain of the neighbor scheme is 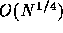 (Makino and
Hut [1988]), and the break-even point is as small as
N=25. For the treecode, the gain is
(Makino and
Hut [1988]), and the break-even point is as small as
N=25. For the treecode, the gain is 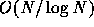 . The break-even
point depends on the required accuracy, but
. The break-even
point depends on the required accuracy, but 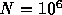 is certainly
large enough to guarantee a pretty large gain.
is certainly
large enough to guarantee a pretty large gain.
However, we (or anybody else) have not yet conceived a feasible way to combine the neighbor scheme and GRAPE, or treecode with individual timestep and GRAPE. In both cases, the problem is that forces on different particles are calculated differently. As a result, n pipelines which calculate the forces on n different particles need n different data from the particle memory, while in the case of the simple direct summation all pipelines can use the same data. In principle, if each pipeline has its own memory, we can reconcile massively parallel GRAPE and these algorithms. With the next-generation system, it will be necessary to integrate the memory and the pipeline processor anyway, since otherwize we cannot achieve required memory bandwidth even for the case of the simple GRAPE architecture. This integrated memory and pipeline might give us the opportunity to implement more efficient force calculation algorithms.