This FY, we have achieved most of what have been originally planned when we started the project, though there has been some delays in achieving the quantitative goals, mainly due to the reduction of the research budget for this FY. The achievements in this year are summarized as follows:
In the following, we briefly describe each of them.
The most important achievement of this year is that we have completed the design and the testing of the prototype system consisting of multiple processor boards and network boards. Figure 5 is the prototype system with 4 processor boards and one network board. This system uses our first prototype version of the processor board with the maximum capacity of 16 processor chips. Thus, the theoretical peak speed of this prototype processor board is about 500 Gflops, and the peak speed of the system shown in figure 5 is 2 Tflops. We have successfully the operation with up to eight boards (figure 6), for the peak speed of 4 Tflops.

Figure 6: Prototype system with eight processor boards
We completed the design of the multi-purpose system. In short, the physical design of the multi-purpose system will be exactly the same as that of the gravity/Coulomb processor, except for the processor module. The processor module of the gravity/Coulomb processor houses 4 GRAPE-6 custom processor chips and memory chips. Instead of the GRAPE-6 processor chips, we will use FPGA chips from Altera (ACEX 2K series) as the processor chips for the processor module of multi-purpose system. The architecture of the FPGA module is similar to the internal design of the GRAPE-6 chip, with memory interface and host interface implemented on a specialized FPGA chip (controller chip) and pipeline units implemented to multiple FPGA chips on module. The sample of FPGA module will be delivered to us in spring 2001.
We have developed the pseudo-particle
multipole method (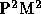 )[Mak99], a novel method to implement high order multipole
expansion using particles. As we have already described in previous
reports,
)[Mak99], a novel method to implement high order multipole
expansion using particles. As we have already described in previous
reports, 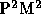 allows us simple and efficient implementation of both
the Barnes-Hut tree algorithm and FMM (fast multipole method), which
allow us to reduce the calculation cost of long-range interaction
from
allows us simple and efficient implementation of both
the Barnes-Hut tree algorithm and FMM (fast multipole method), which
allow us to reduce the calculation cost of long-range interaction
from 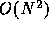 to
to 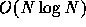 or at least theoretically
or at least theoretically 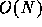 . In
practice, the calculation cost of these methods, in particular when
high accuracy is required, is still high. A important advantage of
. In
practice, the calculation cost of these methods, in particular when
high accuracy is required, is still high. A important advantage of
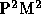 is that it allows us to use special-purpose hardwares designed
to calculate particle-particle interactions to evaluate higher order
multipole expansions. In other words, we can use GRAPE to implement
high-order tree algorithm.
is that it allows us to use special-purpose hardwares designed
to calculate particle-particle interactions to evaluate higher order
multipole expansions. In other words, we can use GRAPE to implement
high-order tree algorithm.
One limitation of the present combination of 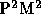 and GRAPE is that
there is no efficient way to implement locally adaptive timesteps
(sometimes called as individual timestep). In many astronomical
systems such as star clusters and galaxies, the orbital timescale of
particles (stars) in them varies by many orders of magnitudes, and
simple algorithms in which all particles share the same timestep
cannot be used. However, it has been difficult to combine tree or FMM
with individual timestep, and no algorithm has been known to combine
individual timestep, tree algorithm and GRAPE.
and GRAPE is that
there is no efficient way to implement locally adaptive timesteps
(sometimes called as individual timestep). In many astronomical
systems such as star clusters and galaxies, the orbital timescale of
particles (stars) in them varies by many orders of magnitudes, and
simple algorithms in which all particles share the same timestep
cannot be used. However, it has been difficult to combine tree or FMM
with individual timestep, and no algorithm has been known to combine
individual timestep, tree algorithm and GRAPE.
We devised a new algorithm, which allows us to combine all three in an efficient manner. It requires small modification of the GRAPE architecture, The overall structure of GRAPE-6 would need no change. The processor module need some change, and we will test the feasibility of this algorithm with FPGA-based system before we actually develop a dedicated system for tree algorithm.
We are awarded this year's Gordon Bell Prize for performance for the simulation of black holes in the core of a galaxy performed on the eight-board system (figure 6). The number of particles used was 768k, and the speed achieved was 1.349 Tflops. This is the first time that the performance number for Gordon Bell Prize exceeded 1 Tflops. The Gordon Bell Prize for performance is given to the calculation with highest sustained speed for real scientific applications. In other words, our eight-board prototype system is already recognized as the machine with the highest sustained speed for scientific applications.