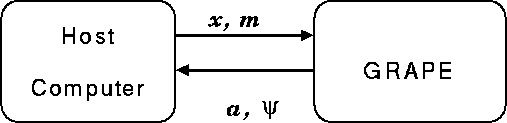We have developed a series of special-purpose computers for N-body simulations, which we call GRAPE (GRAvity PipE). Figure 1 gives the basic idea. The host computer, which is usually a general-purpose workstation running UNIX, send the positions and masses of particles to the GRAPE hardware. Then GRAPE hardware calculates the interaction between particles. What GRAPE hardware calculates is the right hand side of equation (1). When we use the Hermite scheme (Makino [1991b]), the first time derivative of the force must also be calculated. In this case, velocities of particles are needed. Figure 2 shows the block diagram of the pipeline unit to calculate the force and its time derivative.
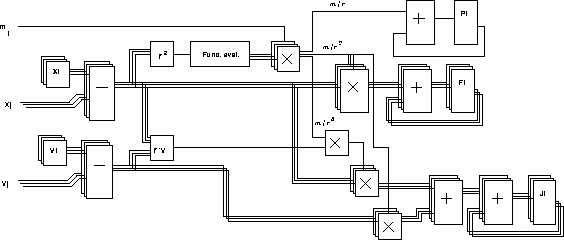
Figure 2: Pipelined processor for the calculation of force and its time
derivative. Reproduced from Makino et al. 1997 [1997]).
In order to combine the individual timestep scheme with GRAPE hardware, one modification of the basic architecture is necessary. Figure 3 shows the change. As described in the previous section, we have to predict the position (and velocity in the case of the Hermite scheme) of all particles to calculate the forces on the particles in the current blockstep. This prediction must also be done on the GRAPE hardware, since otherwize the amount of the calculation the host computer has to do becomes too large.
In the modified architecture shown in figure 3, the particle memory keeps all data necessary for prediction, for all particles in the system. At each blockstep, the host computer writes the position and velocity of particles to be updated, and GRAPE calculates the forces on them and sends the results back to the host. If the number of pipelines is smaller than the number of particles in the block, this step is repeated until the forces on all particles in the block are obtained. Then the host performs the orbit integration using these calculated forces, and updates the data of the integrated particles in the particle memory of the GRAPE hardware.
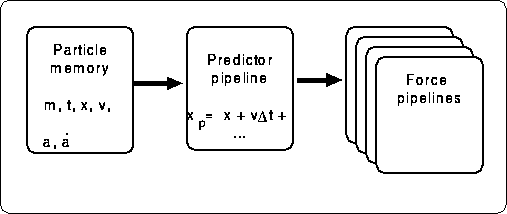
Figure 3: GRAPE for individual timestep
GRAPE-4 (Makino et al. [1997]) is the first GRAPE hardware to implement this modified architecture. In GRAPE-4, one processor board houses one predictor units and 96 (virtual) force calculation pipelines. The total system in the maximum configuration consisted of 36 boards organized into four clusters, and different boards calculated the forces on the same set of 96 particles. In this way, we met the requirement that the number of forces calculated in parallel is small, even though the number of pipelines is large.
Summation of 9 forces from processor boards in the same cluster is taken care by the communication hardware, and final summation of the forces from four clusters is handled by the host.
GRAPE-4 was completed in 1995, and has been used by many researchers for the study of dense stellar systems.